一个好的问题描述有利于社区小伙伴更快帮你定位到问题,高效解决你的问题
【TiDB 使用环境】生产环境
【TiDB 版本】社区版 v7.5.4
【部署方式】阿里云ecs部署
【操作系统/CPU 架构/芯片详情】
【机器部署详情】16c/64G
【集群数据量】 数据量5T多一点
【集群节点数】 4-4-4
【问题复现路径】无
【遇到的问题:问题现象及影响】 DM同步延迟
【其他附件:截图/日志/监控】
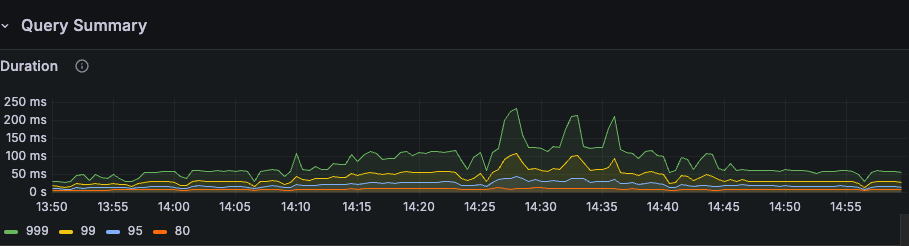
tidb overview
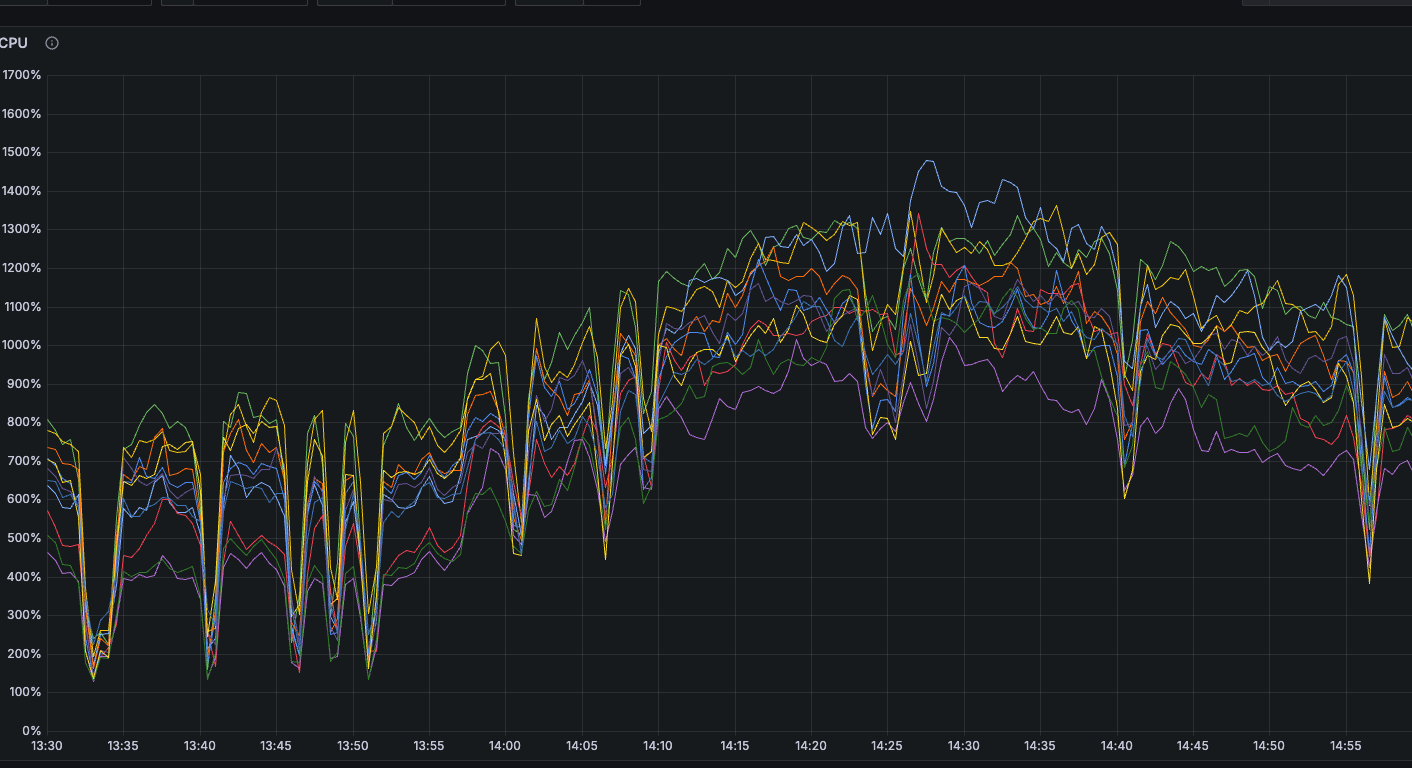
tikv cpu
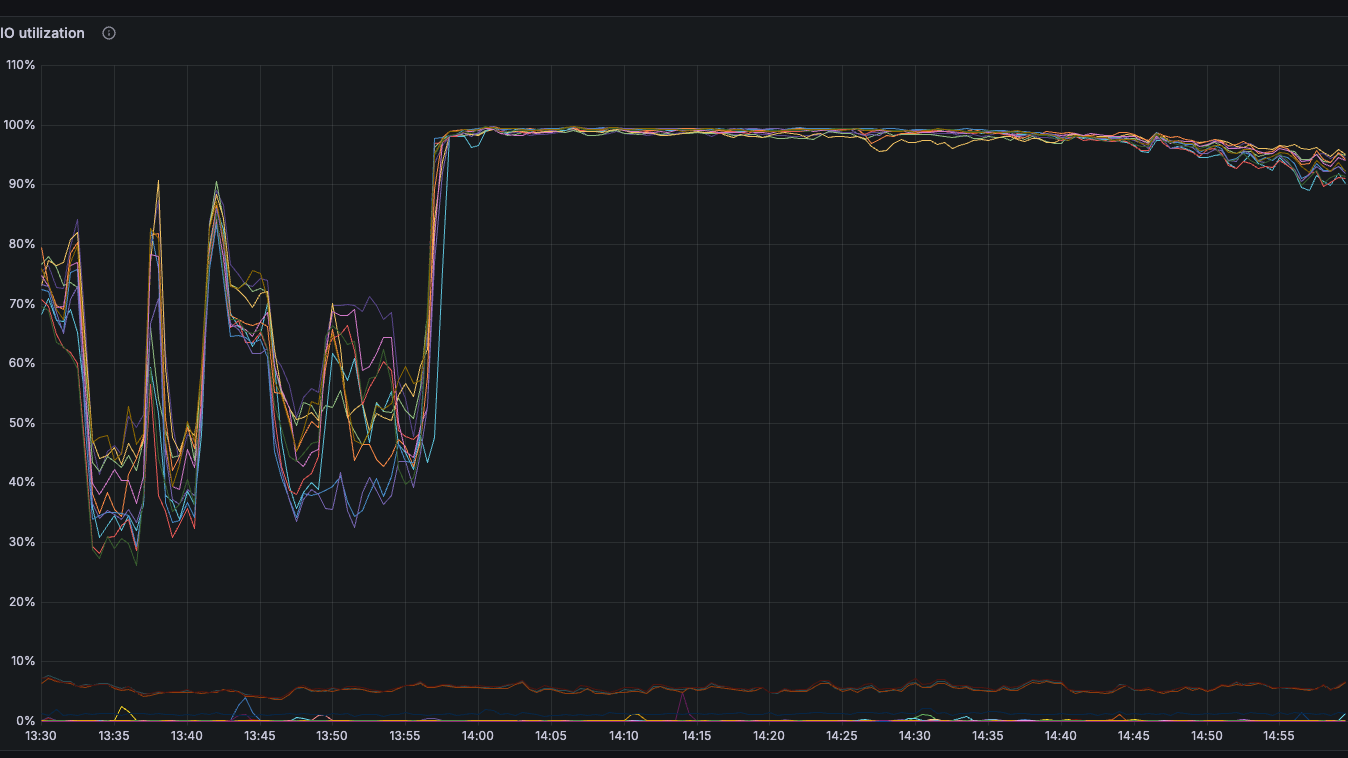
tikv io
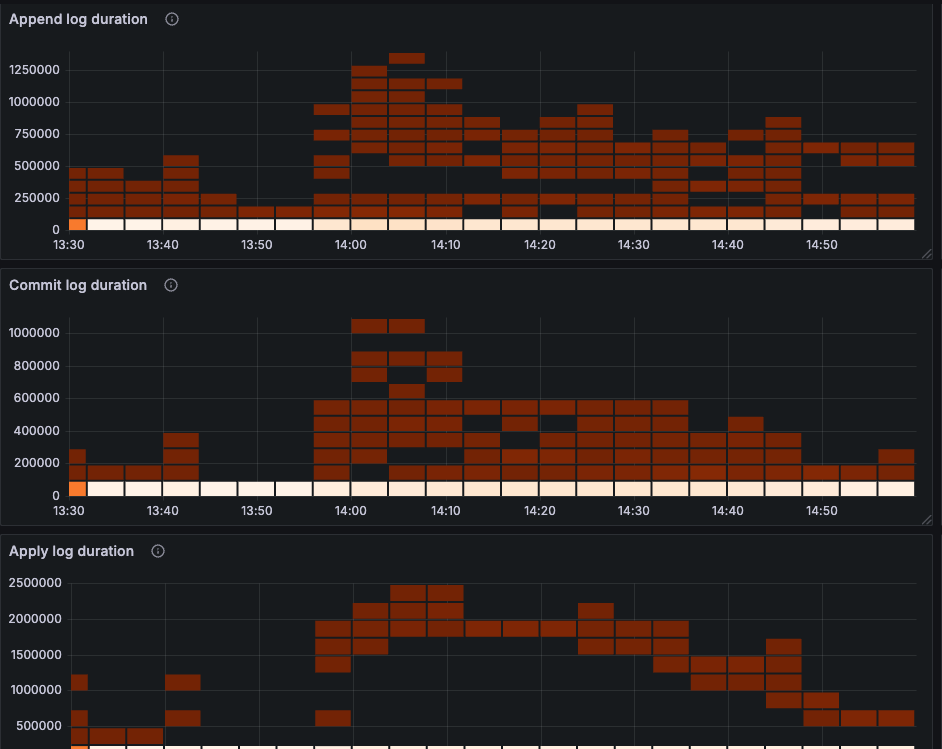
raft io
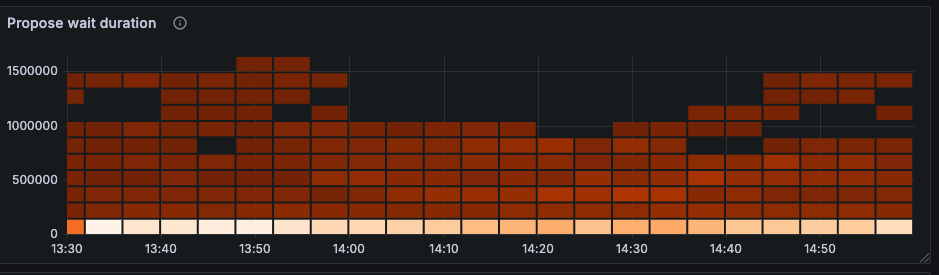
raft propose
补充信息:
当前dm worker进程所在服务器cpu使用率均很低
问题:
1、当前判断是tidb的消费瓶颈,导致dm出现延迟,但是从目前监控看,能看出当前瓶颈是io吗?虽然io util 100%,但是当前磁盘是nvme ssd,不能代表磁盘到瓶颈了,且磁盘吞吐量才100M多一点。 raft 日志写的单位不清楚,不知道是不是社区版的缘故,跟标准版的不一样。
2、tikv层面该时间段均没有如server is buys,或者write stall等信息,只要个位数的drop leader,但是仍然无法证明整个tidb的卡住了。
1 个赞
性能问题建议先看 TiDB Dashboard 的 Top SQL 和慢查询,定位瓶颈在哪一层。常见原因有:热点 Region 没有打散、执行计划不准(analyze table)、或者 TiKV 的 RocksDB 参数没调。
1 个赞
DM 同步延迟的根因,是TiKV 层 IO 响应变慢导致 Raft 日志写入阻塞,进而拖慢了整个写入链路,这是一个典型的 “软 IO 瓶颈”,不是磁盘硬件上限,而是写入放大或热点导致的。
TiDB001
(Ti D Ber G Ec Kbxr N)
8
适当调整transaction-size 参数,以避免单个事务过大导致处理时间延长
从 MySQL 迁到 TiDB,如果原来用了自增主键,高并发下会产生写入热点,因为所有写操作都集中在同一个 Region。建议评估下改成 AUTO_RANDOM 或者业务自己生成分布式ID,利用 TiDB 的 Region 自动拆分机制提高写入吞吐。
狂拽瘸子好腿
(Ti D Ber 8u Uk Olqy)
10
无 server busy、write stall 仅少量 drop leader,无法佐证 TiDB 整体阻塞,需核对 TiDB 执行耗时、raft 同步延迟确认消费瓶颈。
io util=100% 对 NVMe 不能单独证明瓶颈,需用 iostat -x 1 同时看 await、aqu-sz、IOPS/吞吐及设备时延基线。按链路比对 DM 的 binlog 读取、队列和事务执行耗时,TiDB statement latency,以及 TiKV raftstore apply/write、scheduler pending 指标;若 DM worker CPU 低而下游事务耗时和 raft apply 队列同步升高,才可定位为下游反压。还应检查大事务、热点表/Region 和下游 DDL/锁,截取延迟开始时的 DM Grafana 与 query-status,不能仅凭没有 write stall 排除 TiKV。