【TiDB 使用环境】生产环境
【TiDB 版本】v6.5.12
【部署方式】私有云
【操作系统/CPU 架构/芯片详情】rh7 x86_64
【机器部署详情】CPU大小/内存大小/磁盘大小 tidb-server 单节点 16c 40g
【问题复现路径】
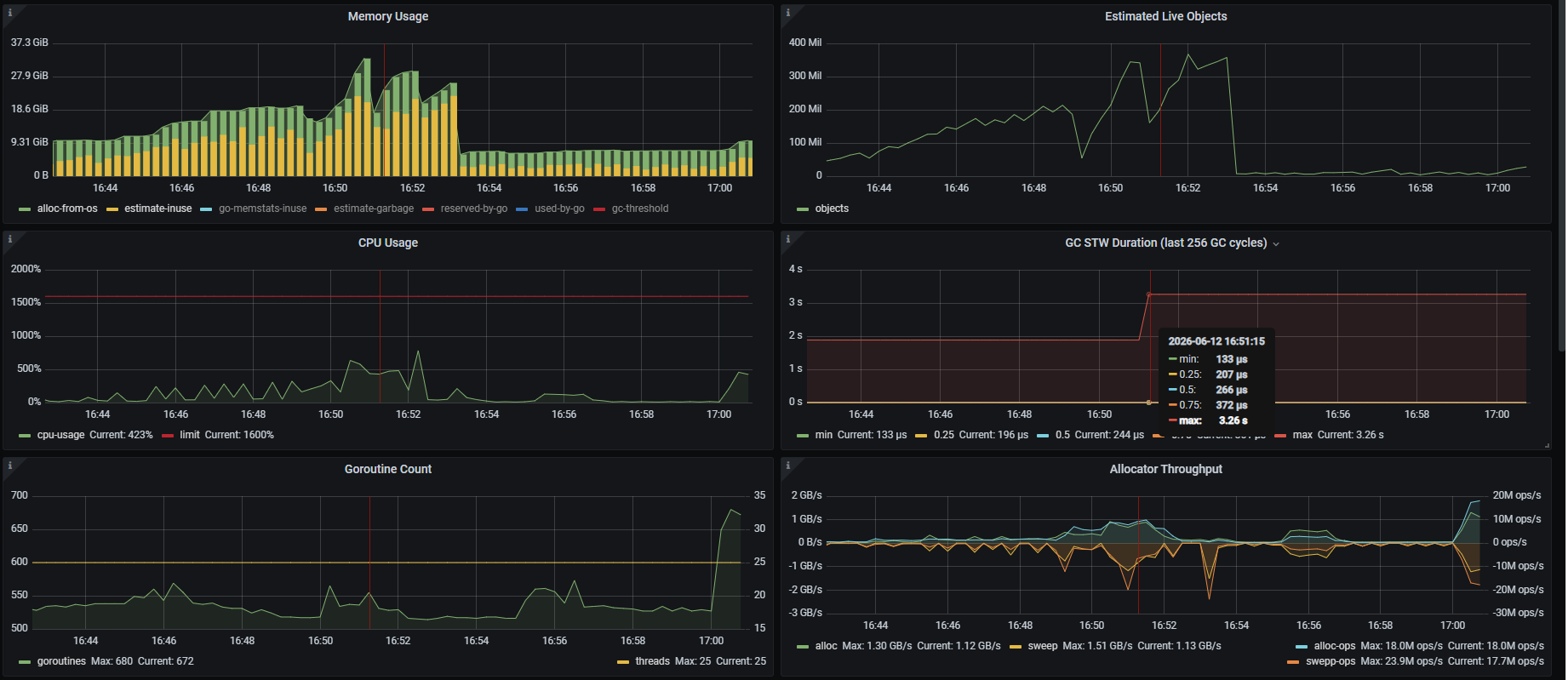
0604 更新
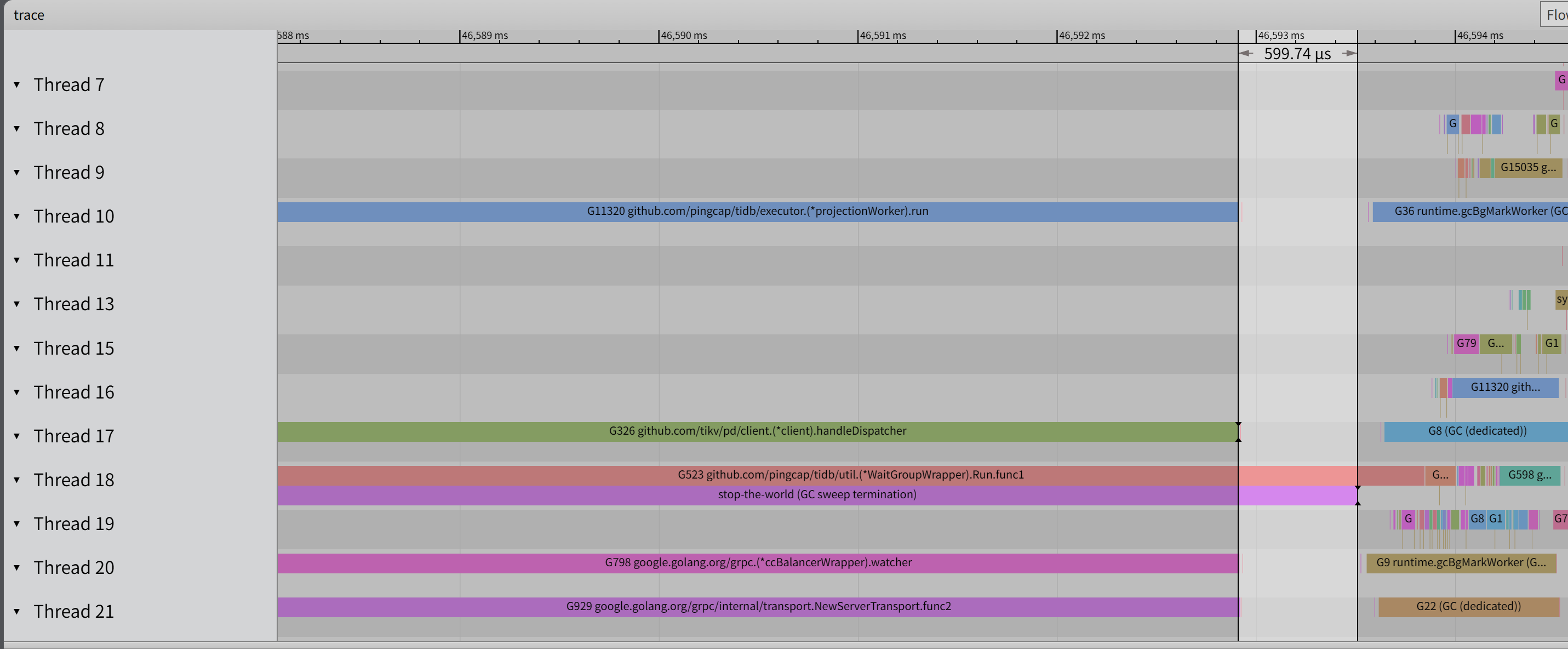
gogc 调整代码限制改成了 25 还是会复现问题,抓了下 trace 很奇怪,STW 期间有几个 goroutine 依然在跑,在 STW 结束前几百纳秒才完成,然后 STW 就结束了,难道是因为这几个 goroutine 停不下来导致的么
trace.zip (27.8 MB)
tidb_server_memory_limit = 30g
tidb_server_memory_limit_gc_trigger = 0.65
tidb_server_memory_limit_sess_min_size = 10g
tidb_enable_gogc_tuner = off
tidb_mem_quota_query = 16g
gogc = 25
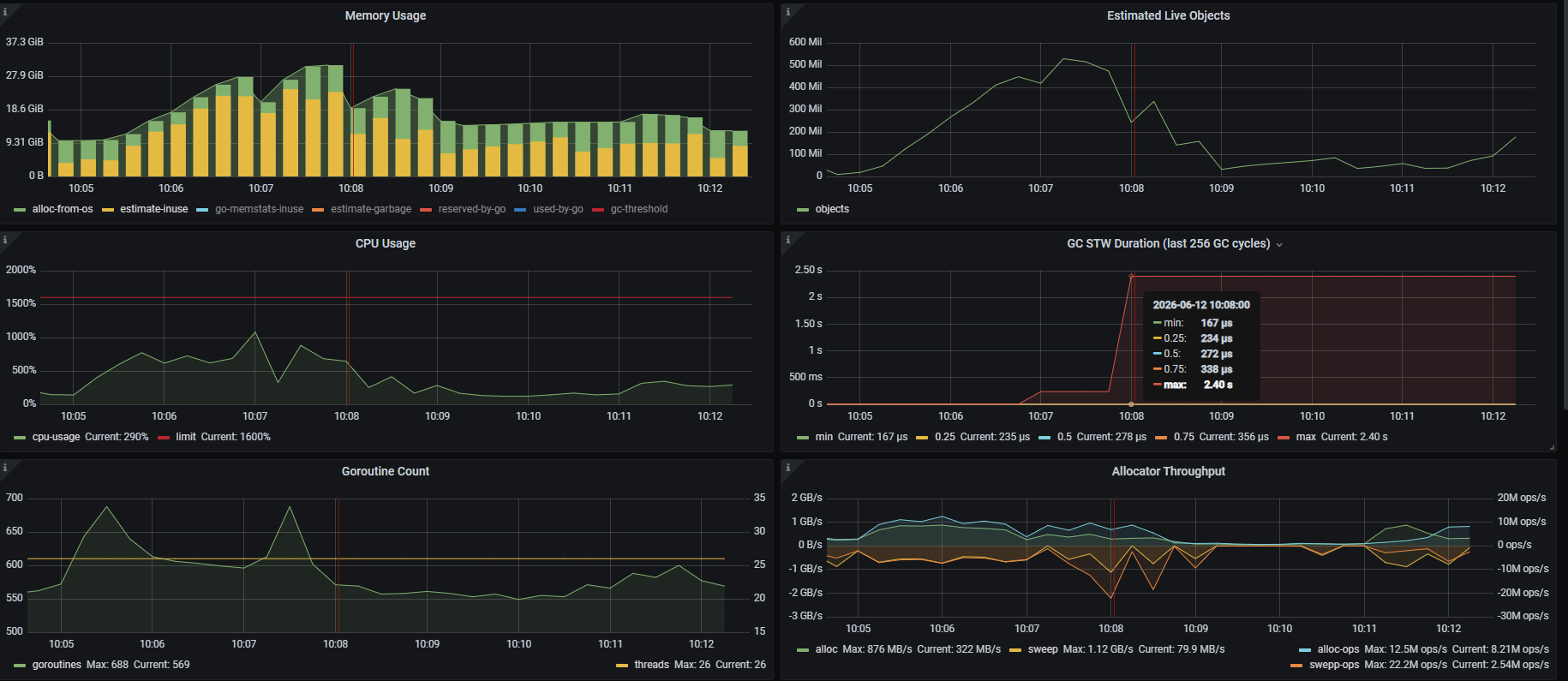
执行单个大查询使节点内存占用达到 32g,sql执行完成后释放内存,发现节点 gogc stw 时间达到秒级,部分 insert update 语句报错 context canceled,gogc 日志中显示在 n-1 次 gc mark 大量内存进行清理后,则第 n次 gc 写屏障的 stw 时间可能很长,怀疑是 n-1 的 sweep 没完成导致的,tidb 是否有参数可以避免这种情况?
[2026/06/12 13:06:56.463 +08:00] [WARN] [pd.go:297] ["get timestamp too slow"] ["cost time"=2.946506746s]
见 gc 18085
gc 18082 @126985.280s 0%: 0.47+4825+0.16 ms clock, 7.5+6687/19008/31878+2.6 ms cpu, 14521->16432->16297 MB, 29044 MB goal, 12 MB stacks, 0 MB globals, 16 P
gc 18083 @127015.517s 0%: 0.95+6208+0.088 ms clock, 15+6.4/24648/47681+1.4 ms cpu, 26655->28790->20511 MB, 31055 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 18084 @127036.176s 0%: 45+3436+0.12 ms clock, 734+27/13671/28572+2.0 ms cpu, 27854->28864->11374 MB, 30996 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 18085 @127046.034s 0%: 2395+3274+0.11 ms clock, 38334+34/13026/32620+1.7 ms cpu, 14797->15145->11570 MB, 15485 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 18086 @127081.063s 0%: 0.71+1938+0.042 ms clock, 11+10/7709/19756+0.68 ms cpu, 19707->20435->9620 MB, 23142 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 18087 @127111.719s 0%: 0.72+1313+0.059 ms clock, 11+3602/5247/10713+0.95 ms cpu, 14258->14273->6467 MB, 17130 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 18088 @127196.353s 0%: 0.73+127+0.031 ms clock, 11+1.2/501/1123+0.50 ms cpu, 11757->11780->6488 MB, 12937 MB goal, 4 MB stacks, 0 MB globals, 16 P
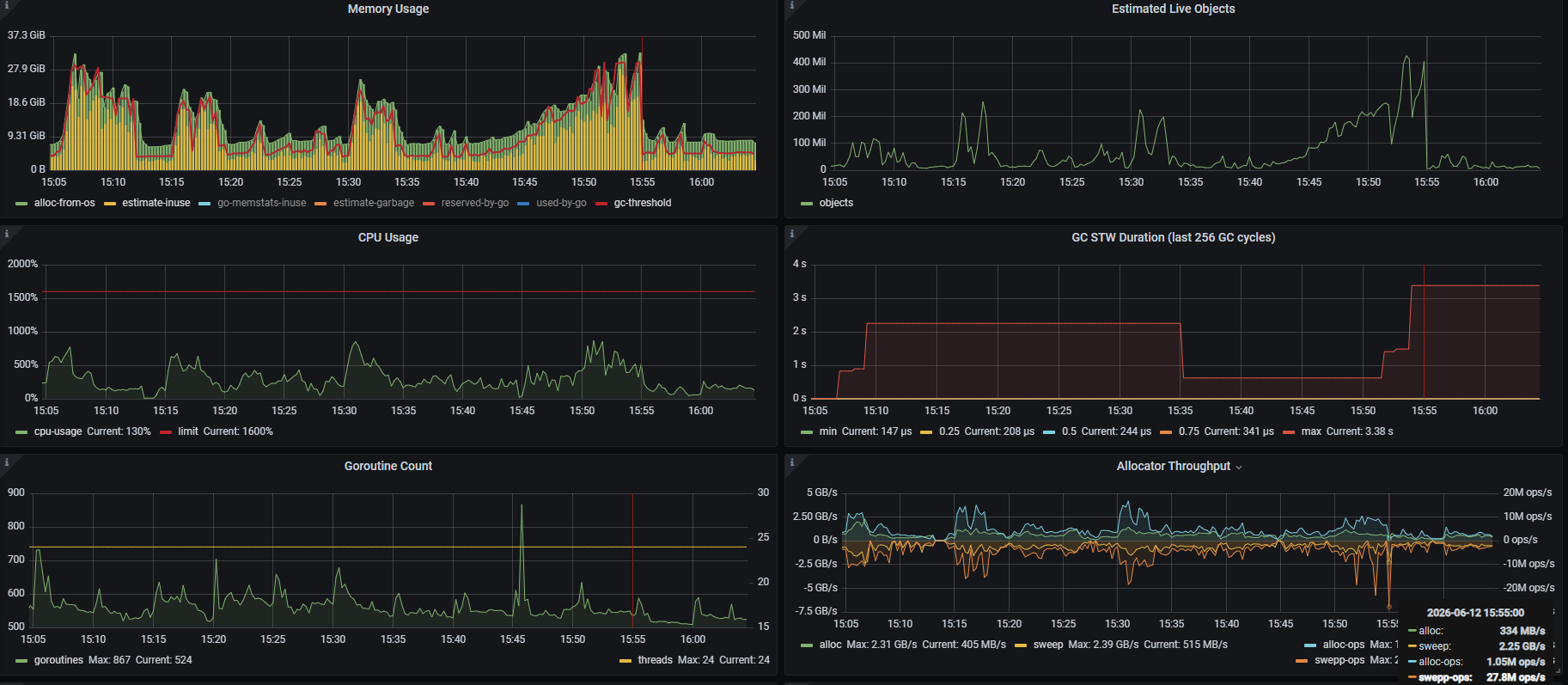
见 gc 4664
gc 4658 @25997.665s 0%: 0.26+674+0.10 ms clock, 4.2+9.6/2684/5426+1.7 ms cpu, 5305->5631->3234 MB, 5743 MB goal, 3 MB stacks, 0 MB globals, 16 P
gc 4659 @26001.805s 0%: 0.24+1056+0.17 ms clock, 3.8+5.8/4193/7926+2.7 ms cpu, 5551->6030->4175 MB, 6470 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4660 @26008.347s 0%: 0.21+1399+0.064 ms clock, 3.3+22/5567/10571+1.0 ms cpu, 7610->8314->4595 MB, 8353 MB goal, 3 MB stacks, 0 MB globals, 16 P
gc 4661 @26014.914s 0%: 230+2510+0.016 ms clock, 3690+3041/7766/14631+0.26 ms cpu, 8040->9351->6237 MB, 9191 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4662 @26027.726s 0%: 0.30+2587+0.072 ms clock, 4.9+14/10273/21461+1.1 ms cpu, 10624->11731->6775 MB, 12476 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4663 @26036.843s 0%: 0.36+3493+0.039 ms clock, 5.7+23/13895/26382+0.63 ms cpu, 11541->13458->8391 MB, 13553 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4664 @26047.182s 0%: 1103+4467+0.071 ms clock, 17658+0/17752/34727+1.1 ms cpu, 15019->16928->11418 MB, 16784 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4665 @26066.998s 0%: 0.45+4527+0.062 ms clock, 7.3+12/17977/36031+1.0 ms cpu, 19449->21891->12383 MB, 22839 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4666 @26085.474s 0%: 0.42+7068+0.072 ms clock, 6.7+975/27971/50439+1.1 ms cpu, 21091->24652->13795 MB, 24768 MB goal, 4 MB stacks, 0 MB globals, 16 P
gc 4667 @26105.509s 0%: 0.55+69+0.12 ms clock, 8.8+14/274/499+1.9 ms cpu, 23496->23555->2201 MB, 27591 MB goal, 3 MB stacks, 0 MB globals, 16 P
gc 4668 @26108.449s 0%: 0.55+54+0.041 ms clock, 8.9+6.8/216/392+0.66 ms cpu, 4267->4293->2045 MB, 4404 MB goal, 3 MB stacks, 0 MB globals, 16 P