是云盘 不是本地ssd
fio_randwrite_result.json (7.5 KB) 这是io
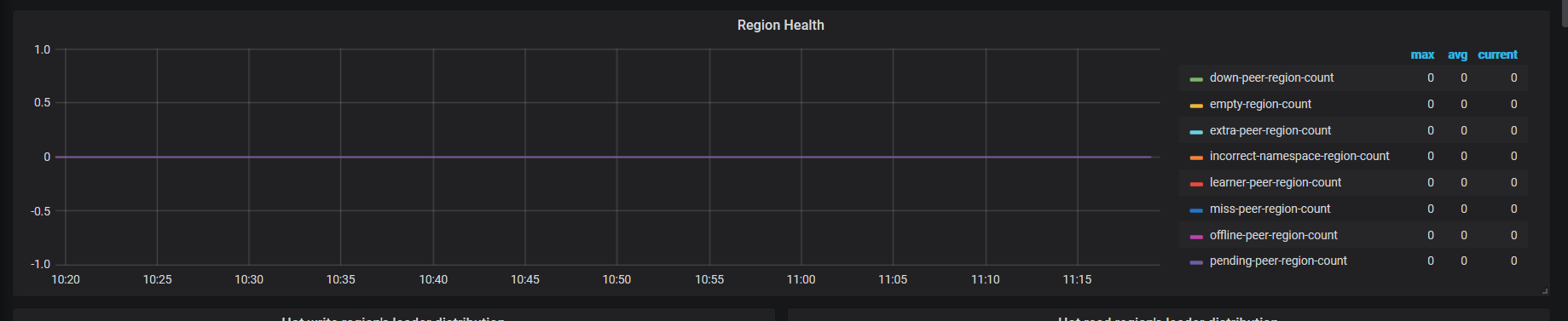
当前无空 region,集群 region 健康。
这个可以上传下,如果非本地 ssd 部署,还是单机多实例,可能出现 io 问题
不是单机多实例 都是单独机器kv
如果除了 tikv 并没有其他服务在运行了,那看下是否可以提高下磁盘的 io 能力吧,云盘建议使用本地 ssd 。
可以在看下 qps 监控,和 tikv io 高节点的 tikv log
我们使用的是阿里的ESSD
如果使用 ESSD 云盘,建议选用 ESSD PL3 类型,描述如下,具体参考阿里云官网文档
适用于中大型核心业务关系型数据库及NoSQL数据库,大型SAP和Oracle系统等。如果您一直使用的是中高级规格(16核vCPU以上)本地SSD实例规格(i1、i2、i2g),可以优先选择ESSD PL3作为数据盘,承载类似的业务系统数据。
阿里是根据磁盘大小来确定规格的,,当时我记得你们的建议是磁盘不要过大。。
是的,
单个 TiKV 数据存储空间越大,后期对 IOPS 性能要求就越高,因此约定了一个上限值,如果单盘测试下来性能 IOPS 满足测试要求 ,也可以超过这个上限;
另外之前设置这个限制还有一个考虑,就是单个 TiKV 的 region 数量过多时,2.1 版本 raftstore 单线程容易成为瓶颈,3.0 版本引入多线程 raftstore 和静默 region 已经优化了这个问题。
好的 我后续在观察
ok~
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。