miniou
(Miniou)
1
【 系统版本 】
CentOS Linux release 7.6.1810 (Core)
【 TiDB 版本 】
TiDB-v4.0.6
【 集群节点分布 】
机器配置统一为
CPU:40vCPU
MEM:128G
SSD:1.4T
内网带宽:1000M
PD+TiDB 合并部署 x3
TiKV x3
【 故障现象 】
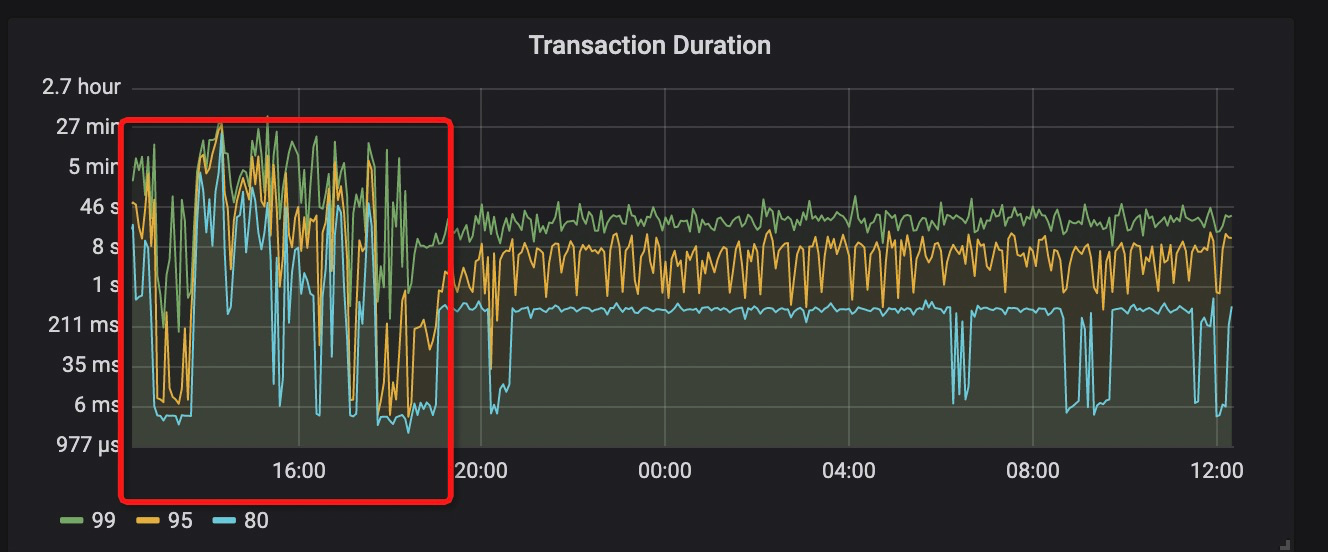
集群运行几天后突然出现SQL查询非常慢,高达分钟或小时级别的现象;
奇怪的是CPU占用非常低,也不存在复杂查询;
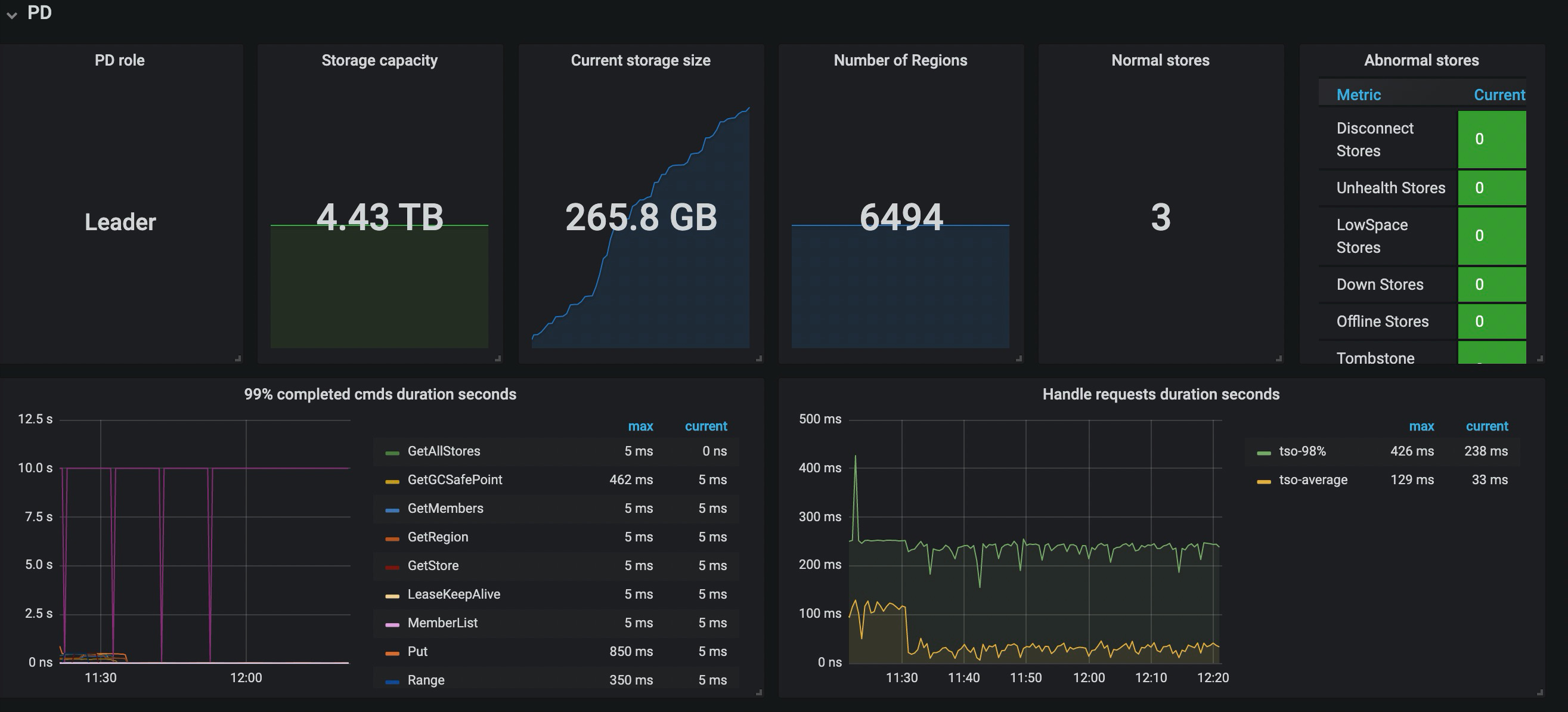
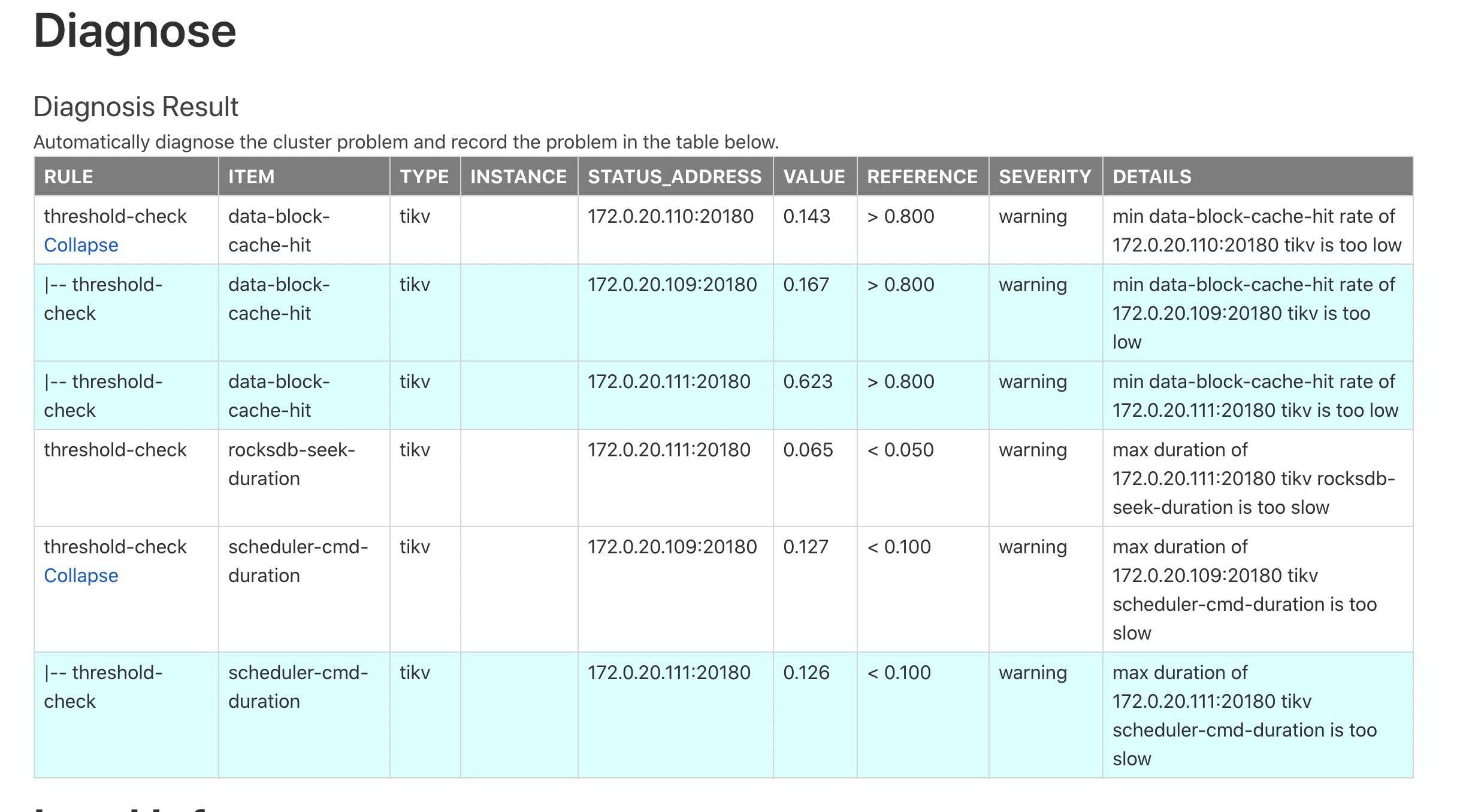
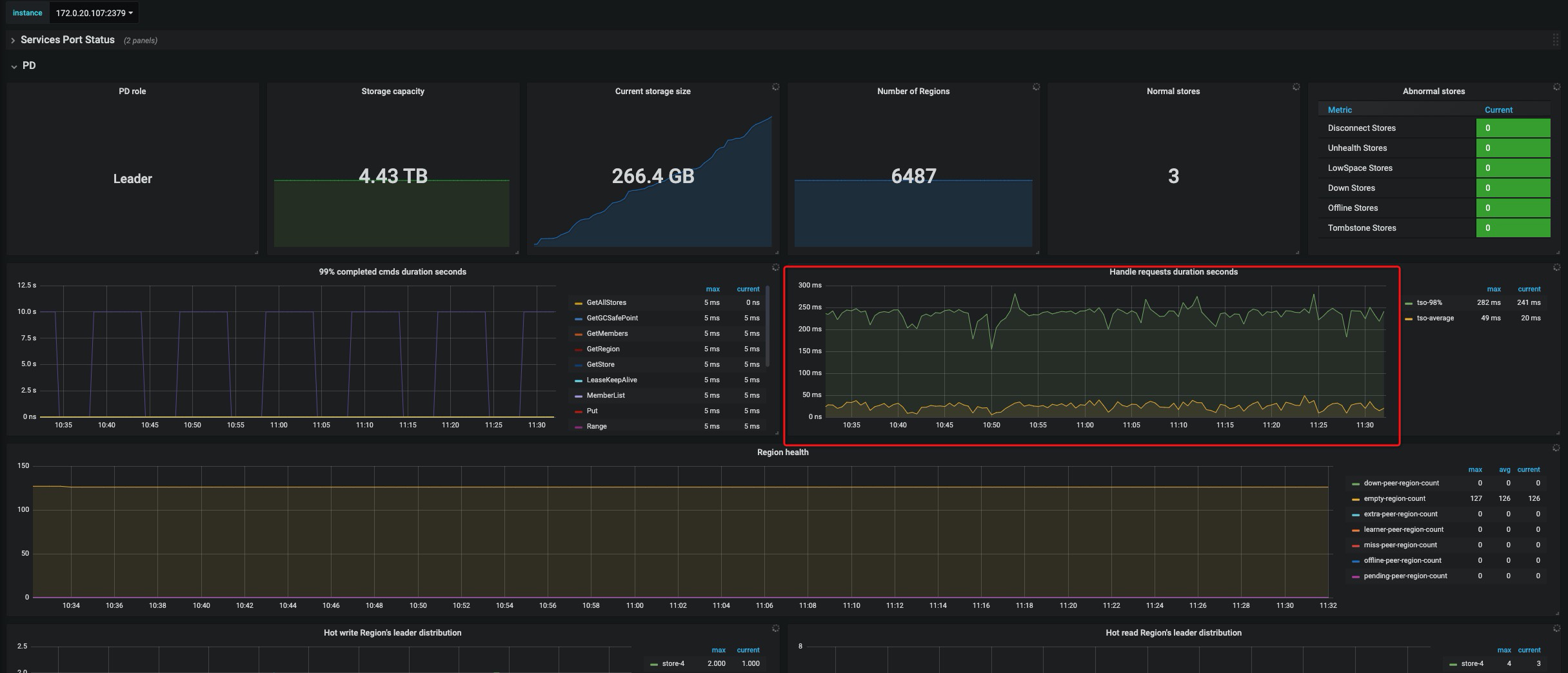
使用Dashboard诊断发现TiKV出现问题;
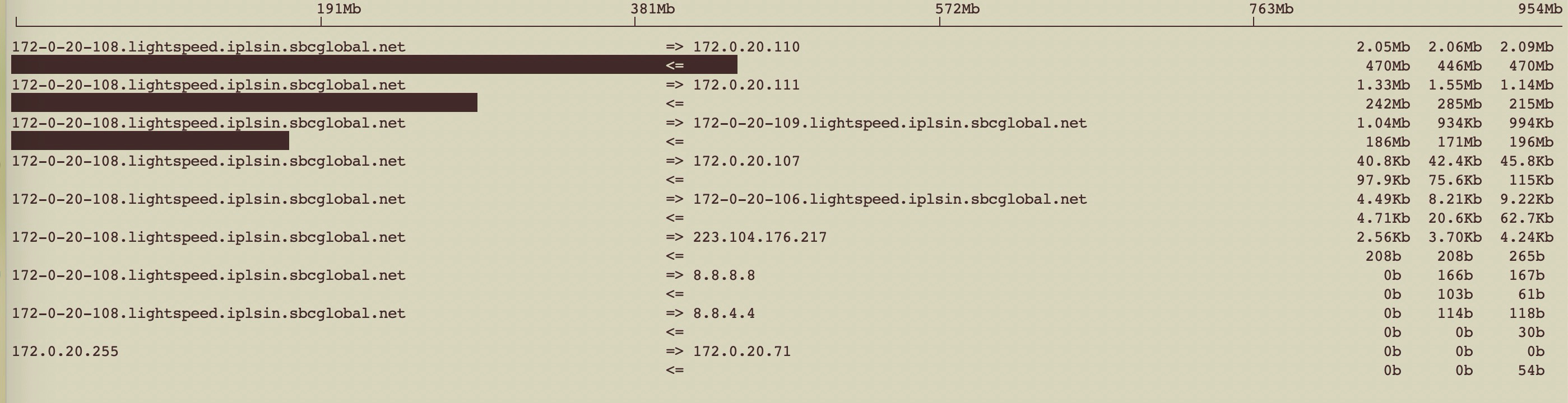
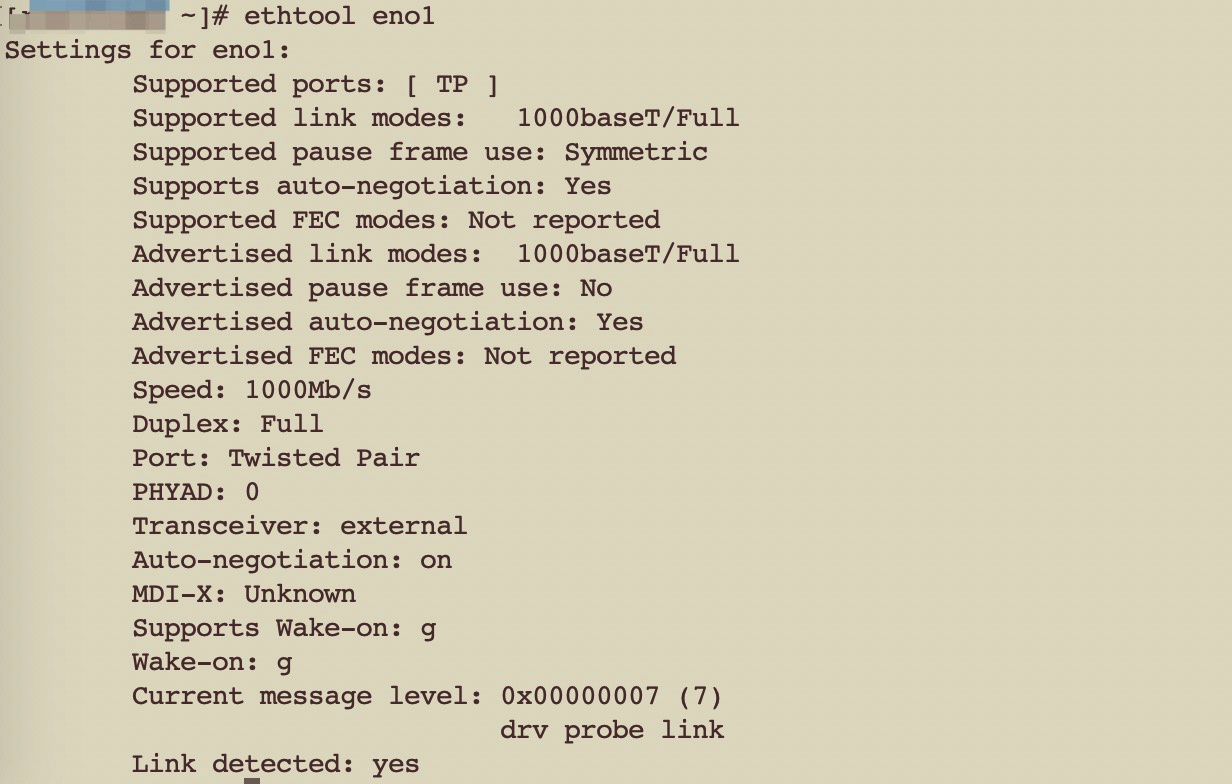
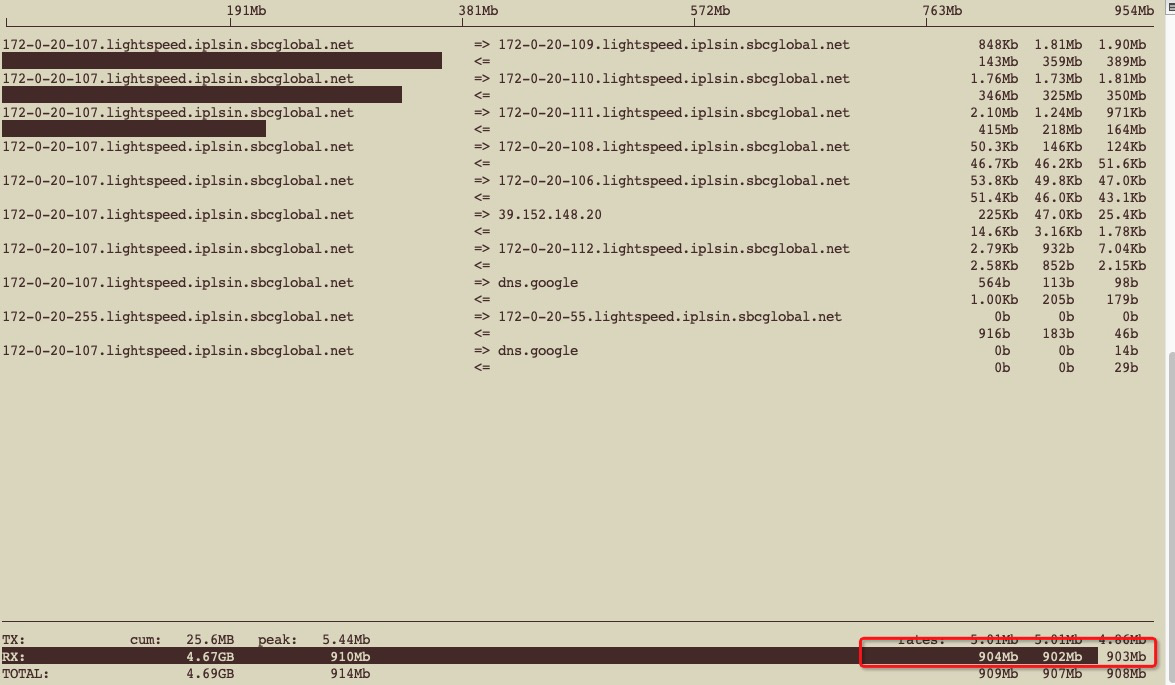
进一步诊断发现其中两台TiDB带宽(1000M)占用非常高,ping其它机器延时高达200ms(正常是0点几ms才对);
nethogs eno1 监控流量如下:
iftop
带宽
【 希望帮助 】
1.流量这么高是否是正常现象
2.如何定位解决并解决问题
spc_monkey
(carry@pingcap.com)
2
1、建议从 慢 SQL 入手,比如创建索引,减少扫描的数据量及传输量
2、只有 2 台高,建议是否可以引入 负载均衡之类的中间件,如果是 tikv 流量高,考虑打散热点
miniou
(Miniou)
3
我们再次定位,不是两台高,是PD Leader所在节点流量高,ping延时非常大,
是否这个原因导致整个集群性能问题,
谢谢。
@miniou 可以发一份出问题时间的诊断报告和之前正常时间段的诊断报告吗?诊断报告直接保存网页即可。 我的邮箱是:chenshuang@pingcap.com
yilong
(yi888long)
7
检查一下带宽占用情况,如果打满了,建议按照标准环境使用万兆网卡,多谢。
@miniou 可以发一份异常时间的诊断报告给我们分析吗?另外麻烦拿下 pd 的 pprof 信息:
curl http://${PDADDR}:2379/debug/pprof/goroutine?debug=1 > goroutine
curl http://${PDADDR}:2379/debug/pprof/profile?seconds=60 > profile
miniou
(Miniou)
9
goroutine (54.8 KB) profile (11.0 KB)
怀疑是网络原因。
TiDB 侧的 kv-get, kv-batch-get 等操作的 P99 耗时超过 10s ,但是 tikv 侧的 grpc_message 的 P99 耗时为几毫秒。TiDB 在 tso_wait 的 P99 耗时也有 1 s, 服务器的 cpu 比价空闲,PD 也没有产生很多调度 operator.