为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:5.7.25-TiDB-v3.0.13
我们生产tidb配置如下:
实例 个数 配置
TIDB 2台 32G/8核
PD 3台 8G/4核(其中两台分布在TIDB2个节点中)
TIKV 3台 32G/8核 - 【问题描述】:怎么在有限的内存下,保证高并发请求?
本公司TIDB应用背景:现在tidb在我们业务中主要担任的角色有
①报表查询、导出功能(占比40%)
②聚合查询业务(提供多表关联复查sql查询,平均每个sql有10个表关联,占比30%)
③其他业务库通过dts(实体同步工具)往tidb同步数据(占比30%)
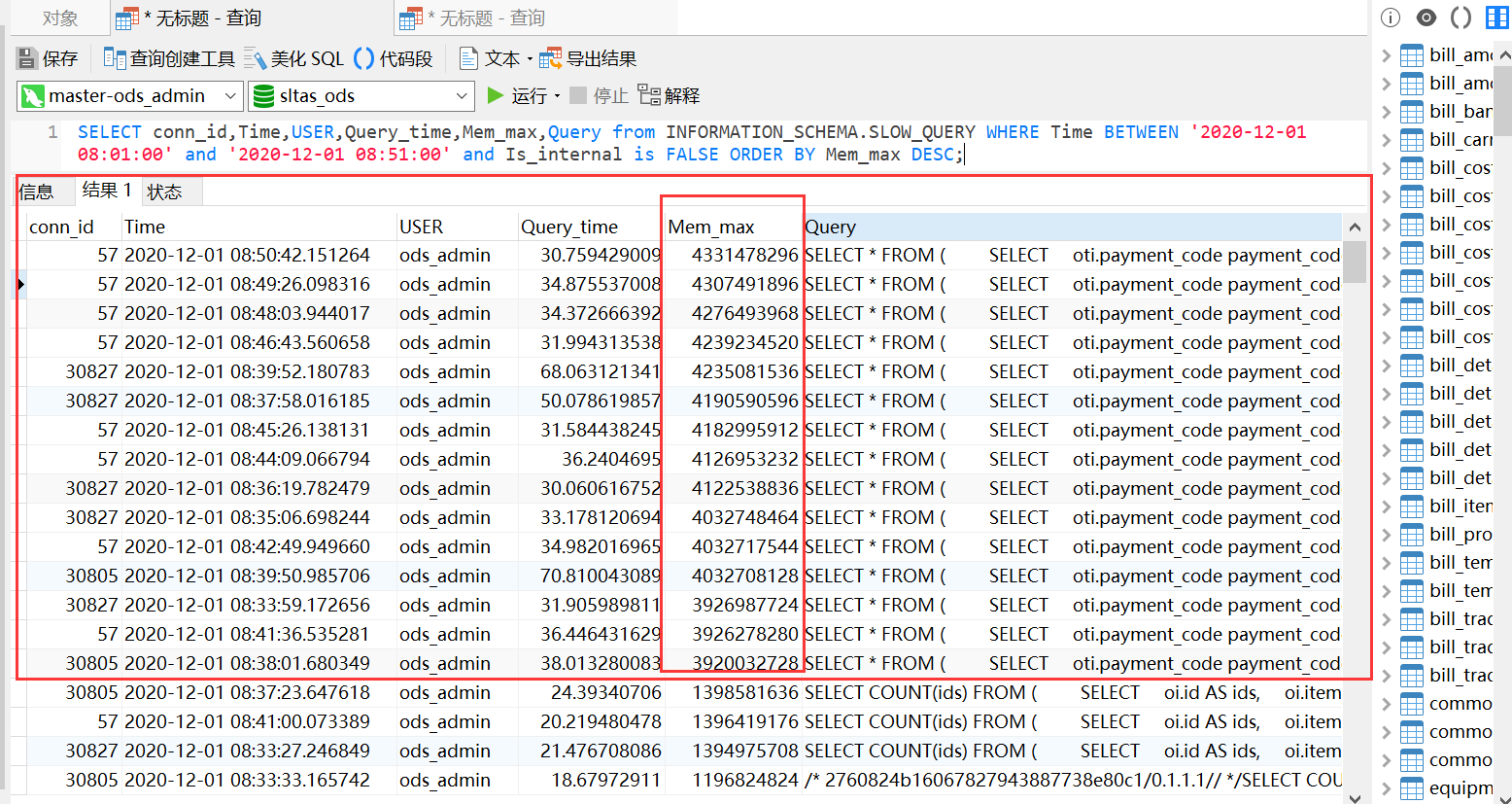
如上图所示:今天早上,有一个报表分页导出功能,按照3万一次,总共20多万数据。执行次数在7次左右,每一次运行4个G内存(sql已经是优化过的,由于关联表多业务复杂没有太多优化空间),时间跨度为12分钟。然后tidb在8点50就出现了宕机。
然后我们查询了下我们gc的设置:发现tikv_gc_life_time 为51m50s
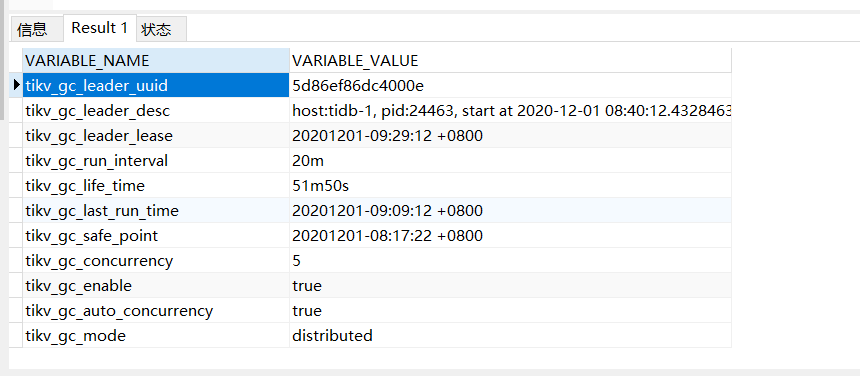
疑问如下:
1、是我们gc时间设置的太长的原因吗?如果我们tikv_gc_life_time调整为10m会进行及时回收资源吗?能避免上面的问题出现吗?
2、如果我们把gc调整为10m,当10分钟内出现大量的耗内存的sql是不是依然内存溢出导致宕机。这种情况下改怎么去优化呢?
辛苦提供下帮助。谢谢