【 TiDB 使用环境】生产环境 or 测试环境 or POC
【 TiDB 版本】
【遇到的问题】
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
1、测试环境
2、5.0.3
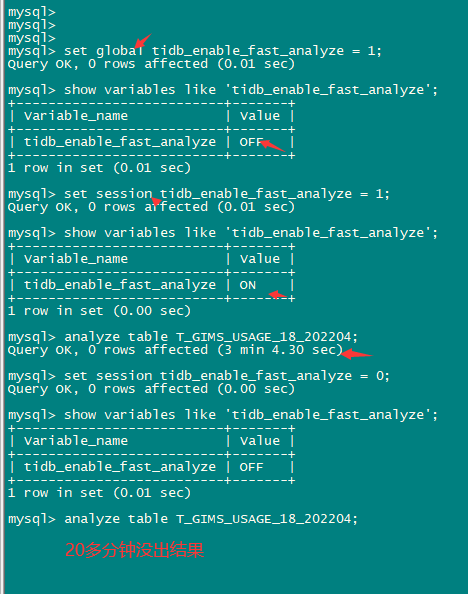
3 analyze table t1已经执行3个小时了。并且是在set global tidb_enable_fast_analyze = 1的情况下。
表大概是有500亿数据,13T,8个tikv节点
4.抽样的统计信息为啥会这么慢。不抽样的话,貌似会跑20个小时左右,并且io也会很高。
虽然知道用抽样统计,没有全量统计收集的统计信息准,但是为了降低对整个系统的影响,因为全量统计信息收集时,io会打满,qps会掉0
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
2 个赞
啦啦啦啦啦
3
tidb_enable_fast_analyze 还是实验特性
调整tidb_build_stats_concurrency这个参数试试呢,需要注意ananlyze并行度设置得更大时,可能也会对其它的查询语句执行性能产生影响。
2 个赞
并发调大吗,并发低的时候,io使用率貌似有点高了。还要再调大,会不会io更高呢
2 个赞
抽样采样还好吧,不是全量,抽样,看官方文档只抽1万条数据
1 个赞
h5n1
(H5n1)
9
SAMPLE采样也会全表扫描收集信息,fast_analyze应该也是不起作用的
1 个赞
其实也就是说设置tidb_enable_fast_analyze=1 对加快统计信息的收集几乎没有任何帮助了吗,因为这个表很大,收集统计信息的话,耗费时间很长,并且统计信息在收集时,io也很高,也不能随意调大并发量(tidb_build_stats_concurrency, tidb_distsql_scan_concurrency),这个该怎么办
1 个赞
h5n1
(H5n1)
14
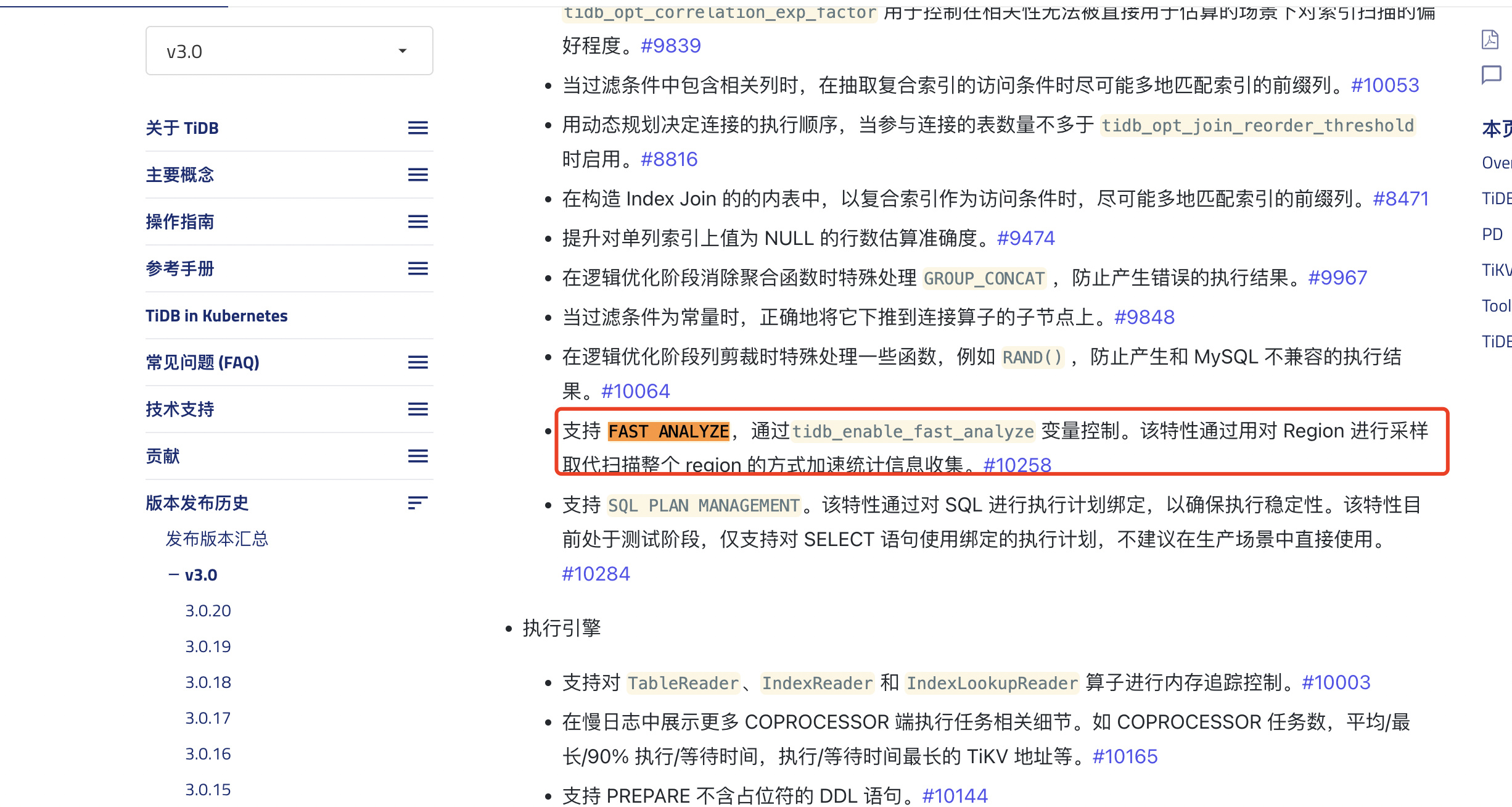
fast analyze 不是指的收集时随机采样10000行,应该是每个region上随机采样后保留10000行的数据做统计信息,非fast时 是扫描所有region上的key
最终执行(25 min 33.53 sec)
1 个赞
雪落香杉树
15
看下analyze的设置
SHOW VARIABLES LIKE '%analyze%'
1 个赞
root@(none) 05:19:42>SHOW VARIABLES LIKE ‘%analyze%’
→ ;
±-----------------------------±------------+
| Variable_name | Value |
±-----------------------------±------------+
| tidb_auto_analyze_end_time | 23:59 +0000 |
| tidb_auto_analyze_ratio | 0.5 |
| tidb_auto_analyze_start_time | 00:00 +0000 |
| tidb_enable_fast_analyze | ON |
±-----------------------------±------------+
”
1 也就是说fast analyze 也会减少 analyze 时总的时间消耗,对吗?
2 “应该是每个region上随机采样后保留10000行的数据做统计信息" 这句话的意思是说,在fast analyze 时每个region 也是全部扫描key的,但是会保留1万条数据做分析,是这样的吗?
3 5.4的意思是扫描部分key,但是我看3.0的新特性也有的。
h5n1
(H5n1)
18
1.从测试上看是这样。
2 、 是所有region上随机采样部分key。非fast时扫描所有region的所有key
3、 5.4 /3.0那个是搜索结果跳转显示问题,是3.0后开始有的。
[quote=“TiDBer_2X9OVSaV, post:17, topic:664222”]
3.0开始有的?3.0和5.4有啥不一样吗?看文字描述是差不多的。
那其实3.0也是采样扫描了。那我的版本是5.0.3,也是扫描部分region了。那为啥这么慢啊