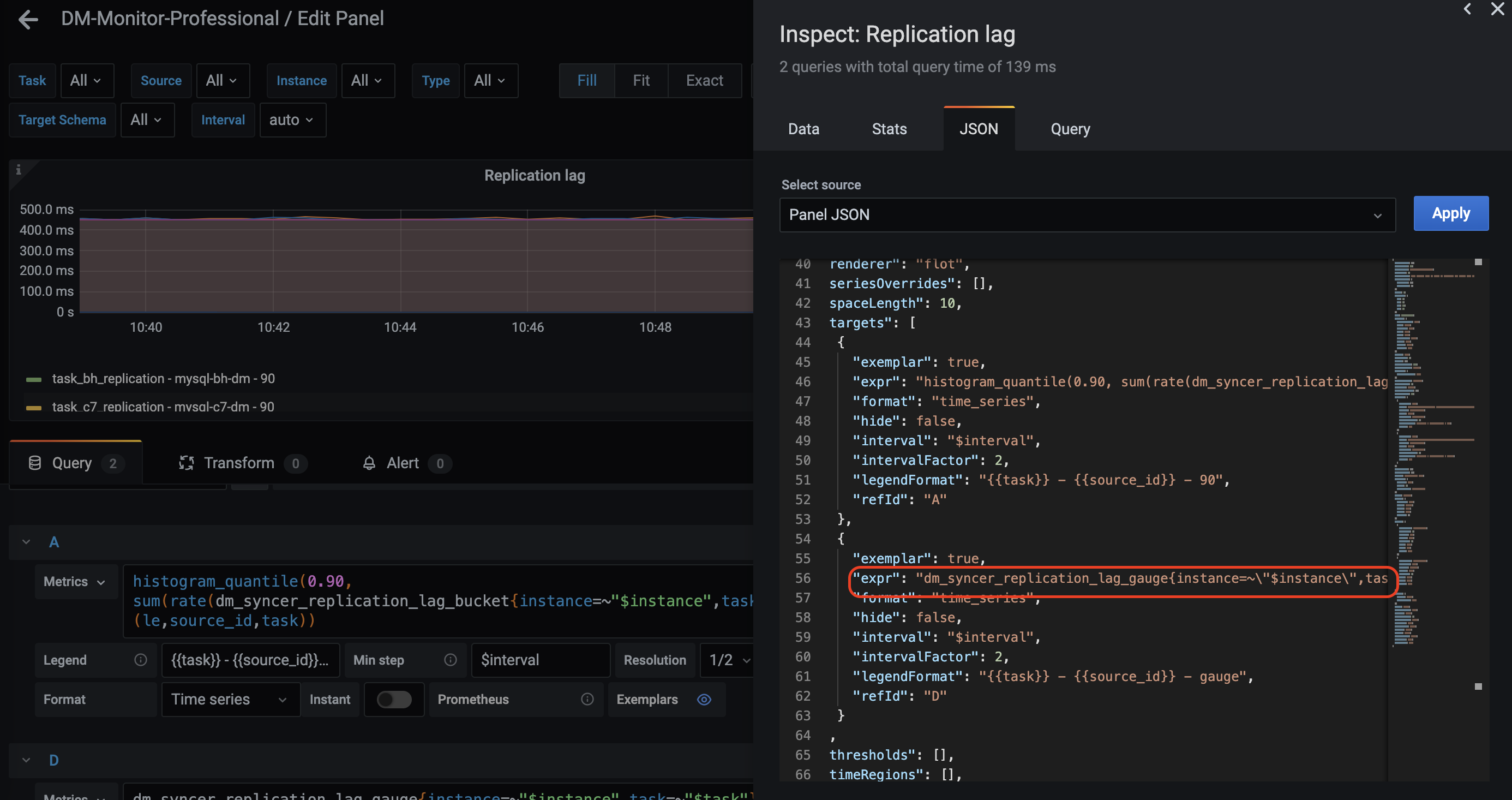
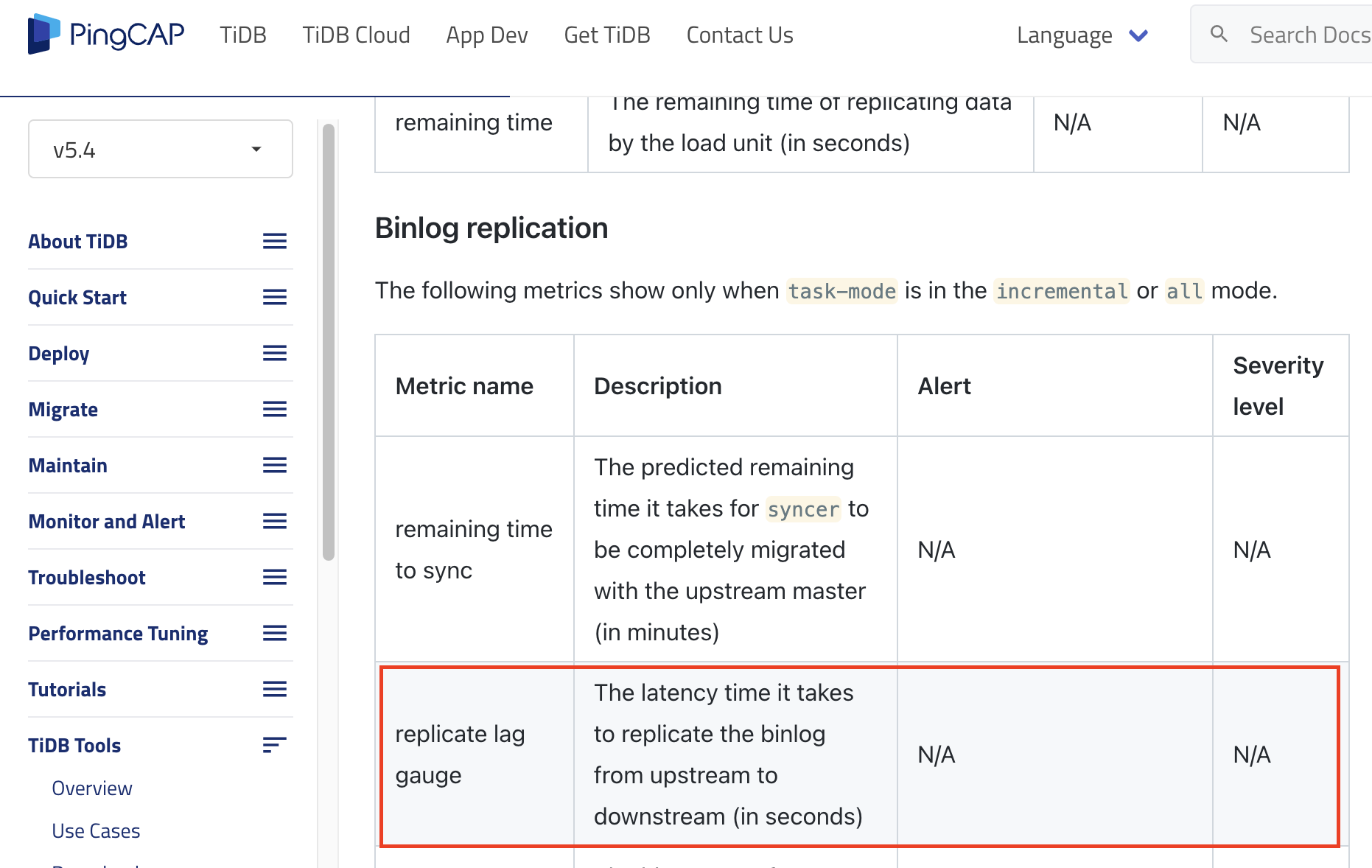
- alert: DM_worker_replication_lag_warning
expr: dm_syncer_replication_lag_gauge{job="dm_worker"} > 10
for: 1m
labels:
level: warning
annotations:
summary: DM replication lag more than 10s and exceed 1 minute
description: 'task: {{ $labels.task }}, Lag: {{ $value }}'
- alert: DM_worker_replication_lag_critial
expr: dm_syncer_replication_lag_gauge{job="dm_worker"} > 30
labels:
level: critical
annotations:
summary: DM replication lag more than 30s
escription: 'cluster: xxxxx-dmcluster, task: {{ $labels.task }}, Lag: {{ $value }}'
alertmanager.yml
需加上routes這個tag下的內容
global:
# 未收到標記告警通知,等待 timeout 時間之後事件標記為 resolved
resolve_timeout: 5m
# The Slack webhook URL.
slack_api_url: 'https://hooks.slack.com/services/T43QNF23S/B02RNU7CJEL/xxxxxxxxxxxxx'
route:
# A default receiver
receiver: "db-alert-slack"
# The labels by which incoming alerts are grouped together. For example,
# multiple alerts coming in for cluster=A and alertname=LatencyHigh would
# be batched into a single group.
group_by: ["env", "instance", "alertname", "type", "group", "job"]
# When a new group of alerts is created by an incoming alert, wait at
# least 'group_wait' to send the initial notification.
# This way ensures that you get multiple alerts for the same group that start
# firing shortly after another are batched together on the first
# notification.
group_wait: 30s
# When the first notification was sent, wait 'group_interval' to send a batch
# of new alerts that started firing for that group.
group_interval: 3m
# If an alert has successfully been sent, wait 'repeat_interval' to
# resend them.
repeat_interval: 3m
routes:
# replication
- match_re:
alertname: DM_worker_replication_lag_warning | DM_worker_replication_lag_critical
group_by: [alertname, task]
receivers:
- name: 'db-alert-slack'
slack_configs:
- channel: '#xxxxx-dm-alert'
title: '{{ .CommonLabels.alertname }}'
text: '{{ .CommonAnnotations.summary }} {{ .CommonAnnotations.description }}'
send_resolved: true