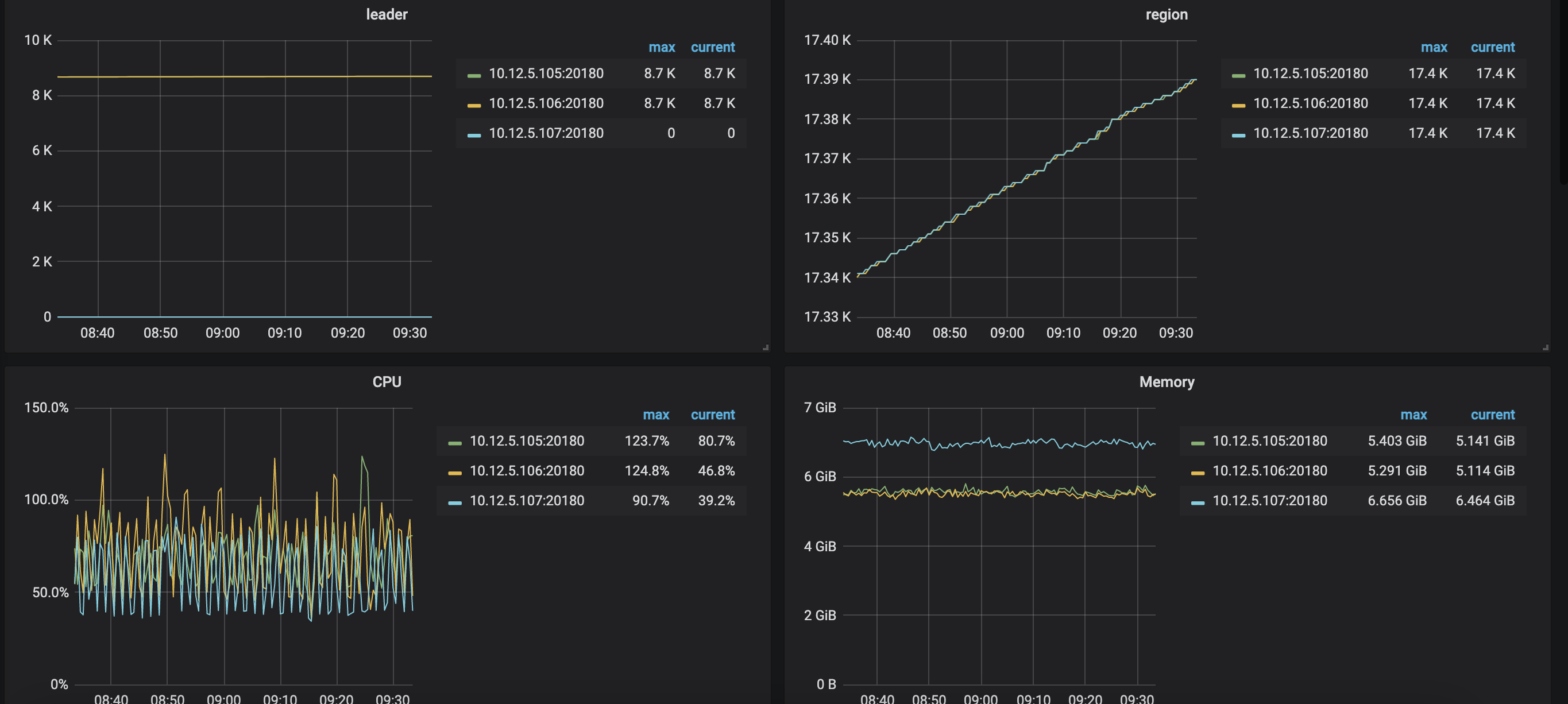
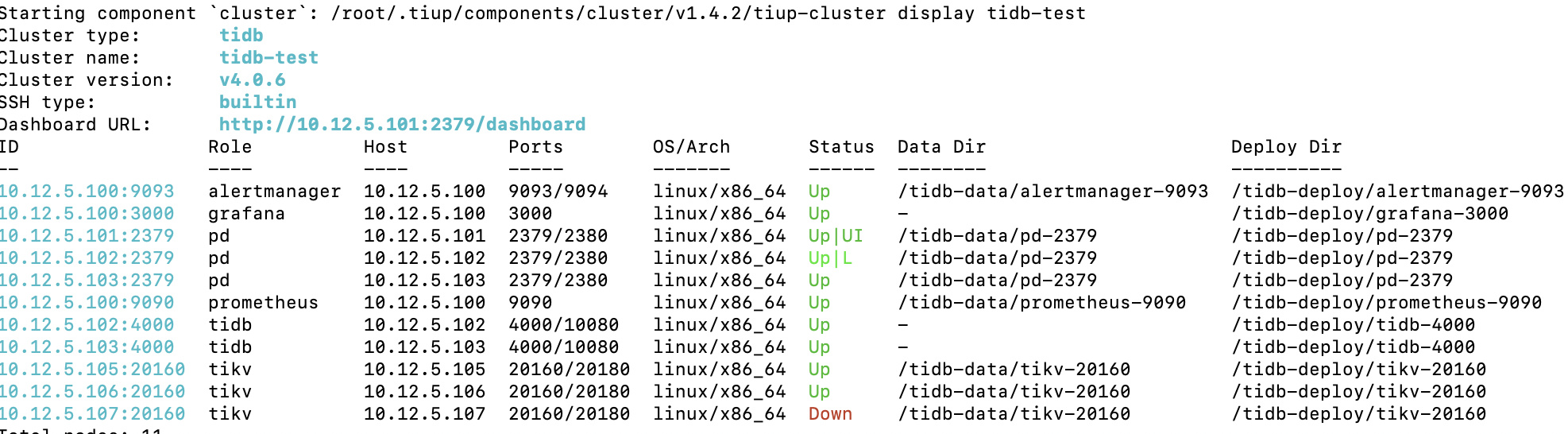
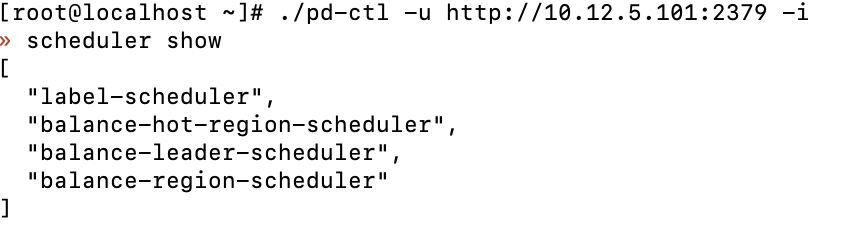
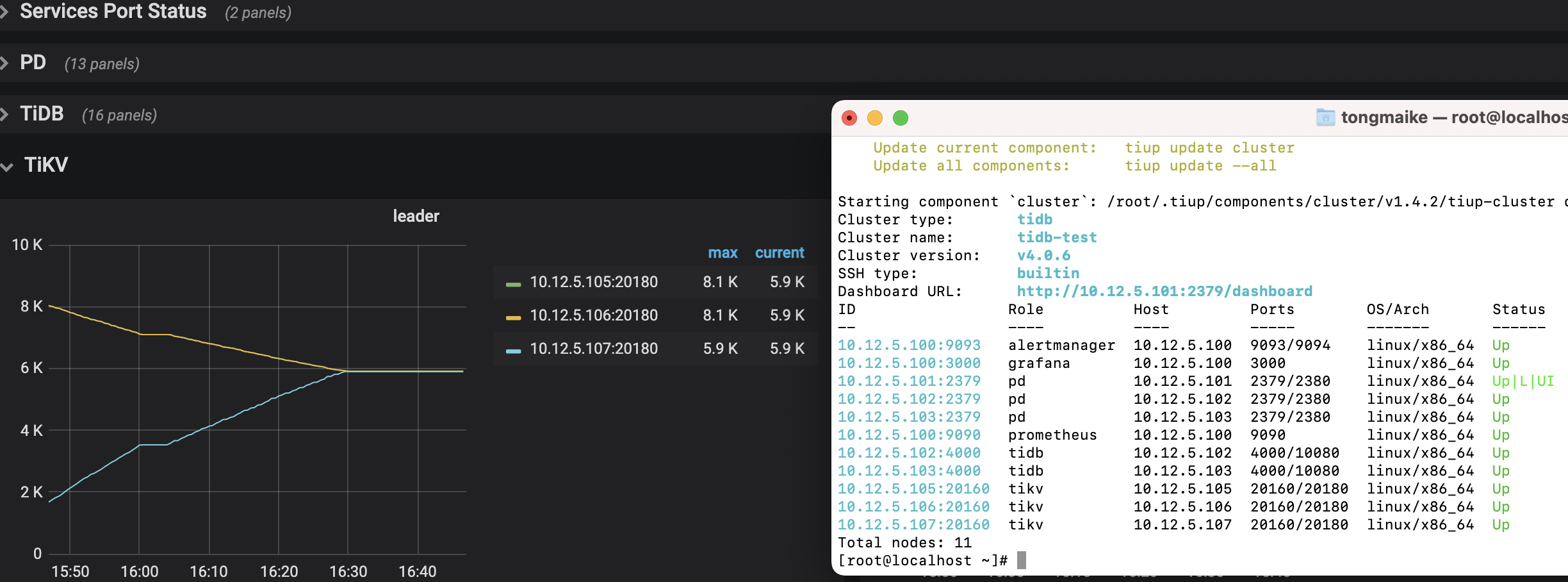
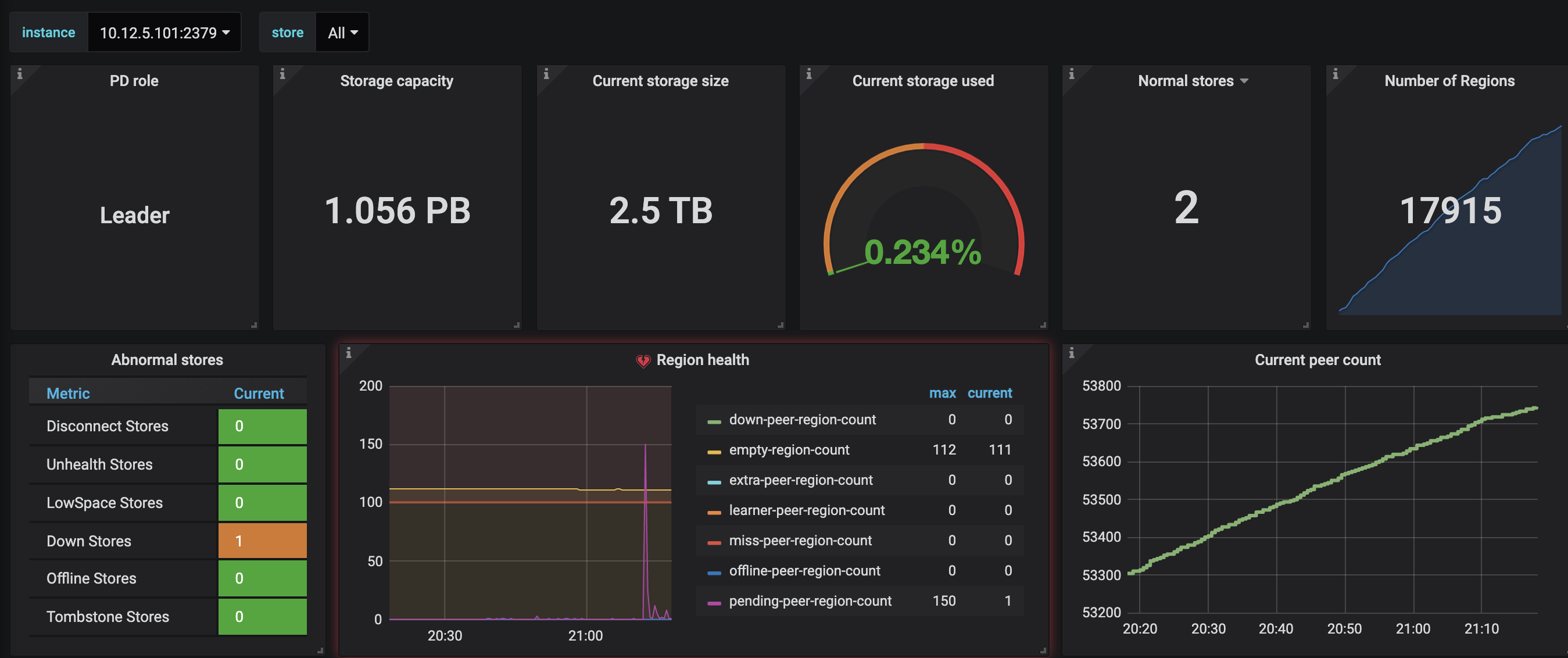
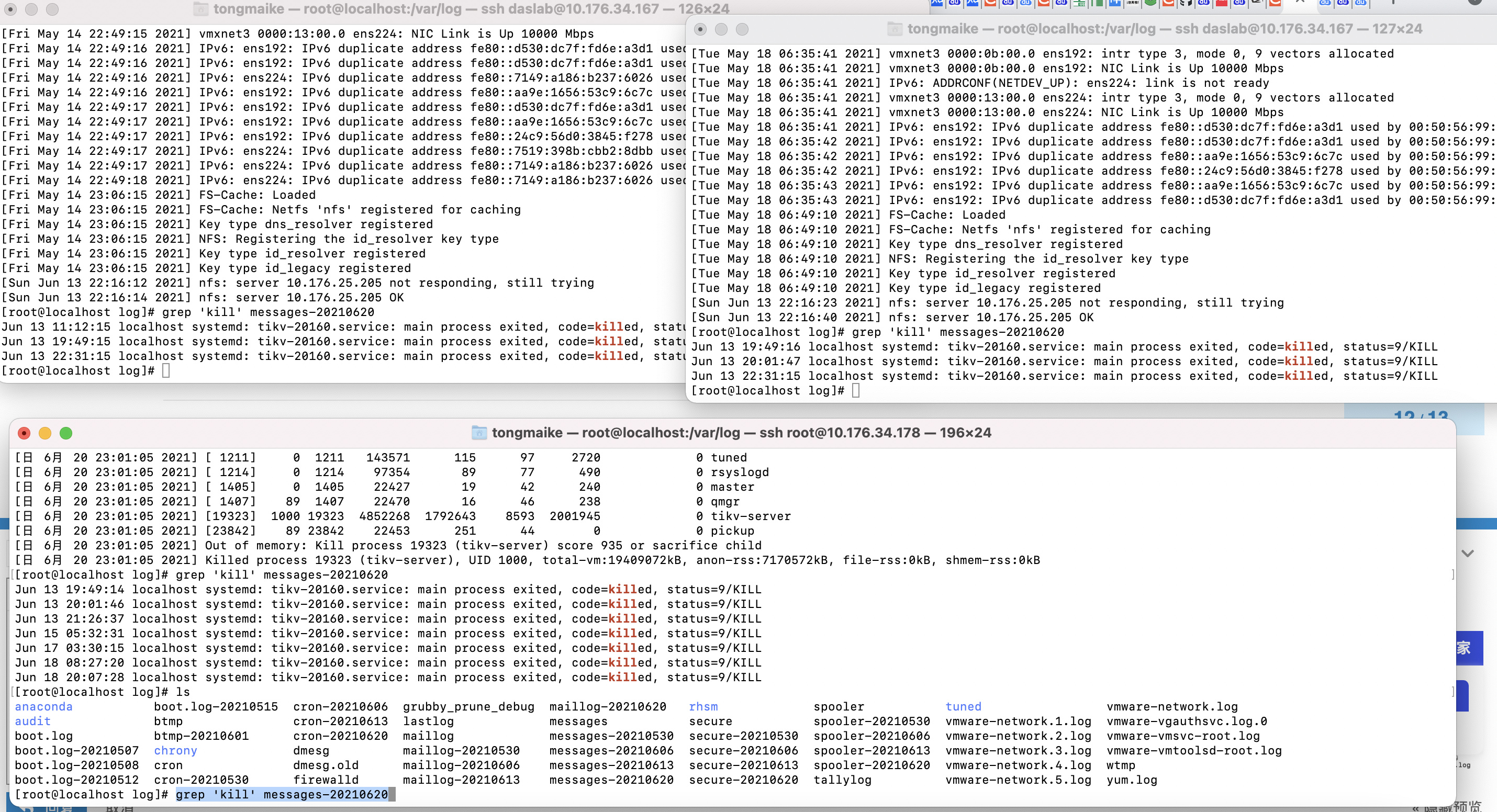
参考了一下其他帖子leader为0的问题,检查了一下调度器,并没有evict-leader-scheduler调度器
store状态如下:
store
{
“count”: 3,
“stores”: [
{
“store”: {
“id”: 5,
“address”: “10.12.5.106:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.106:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1623638213,
“deploy_path”: “/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1623938472359532544,
“state_name”: “Up”
},
“status”: {
“capacity”: “320TiB”,
“available”: “288.7TiB”,
“used_size”: “756.9GiB”,
“leader_count”: 8812,
“leader_weight”: 1,
“leader_score”: 8812,
“leader_size”: 828450,
“region_count”: 17630,
“region_weight”: 1,
“region_score”: 1658159,
“region_size”: 1658159,
“start_ts”: “2021-06-13T22:36:53-04:00”,
“last_heartbeat_ts”: “2021-06-17T10:01:12.359532544-04:00”,
“uptime”: “83h24m19.359532544s”
}
},
{
“store”: {
“id”: 1,
“address”: “10.12.5.107:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.107:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1623749819,
“deploy_path”: “/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1623783687842065651,
“state_name”: “Down”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 17630,
“region_weight”: 1,
“region_score”: 1658159,
“region_size”: 1658159,
“start_ts”: “2021-06-15T05:36:59-04:00”,
“last_heartbeat_ts”: “2021-06-15T15:01:27.842065651-04:00”,
“uptime”: “9h24m28.842065651s”
}
},
{
“store”: {
“id”: 4,
“address”: “10.12.5.105:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.105:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1623638193,
“deploy_path”: “/tidb-deploy/tikv-20160/bin”,
“last_heartbeat”: 1623938473296622285,
“state_name”: “Up”
},
“status”: {
“capacity”: “320TiB”,
“available”: “288.7TiB”,
“used_size”: “756GiB”,
“leader_count”: 8818,
“leader_weight”: 1,
“leader_score”: 8818,
“leader_size”: 829709,
“region_count”: 17630,
“region_weight”: 1,
“region_score”: 1658159,
“region_size”: 1658159,
“start_ts”: “2021-06-13T22:36:33-04:00”,
“last_heartbeat_ts”: “2021-06-17T10:01:13.296622285-04:00”,
“uptime”: “83h24m40.296622285s”
}
}
]
}