
背景
在分布式数据库中,存储节点扩缩容不仅仅是硬件资源的增减,更伴随着大规模的数据再平衡(Rebalance)。如果缺乏精细控制,触发大量的数据副本迁移(Peer 移动),消耗大量的磁盘 I/O、CPU 和网络带宽,会直接冲击生产应用 SQL 语句执行时的延迟表现。常用的控制手段是配置调度参数,但是实践过程中仍会出现参数需要不断地测试最佳值,并且也无法根据负载实现自适配。
在 TiDB 集群的节点扩缩容过程中,Placement Rules 特性赋予操作者精细控制数据调度的能力,确保集群在拓扑变化时依然能够维持性能最优和高可用性,Placement Rules 能够指导 PD (Placement Driver) 如何将数据副本智能地迁移和重新分布,而不是简单地、无差别地进行数据均衡。
技术方案
Placement Rules 的基础操作
在 dashboard 中或者 tiup cluster display <clustername> --labels 命令可以查看 TiKV 实例的标签关系。如果节点标签未配置,可以用 PD Control 工具在线进行配置。
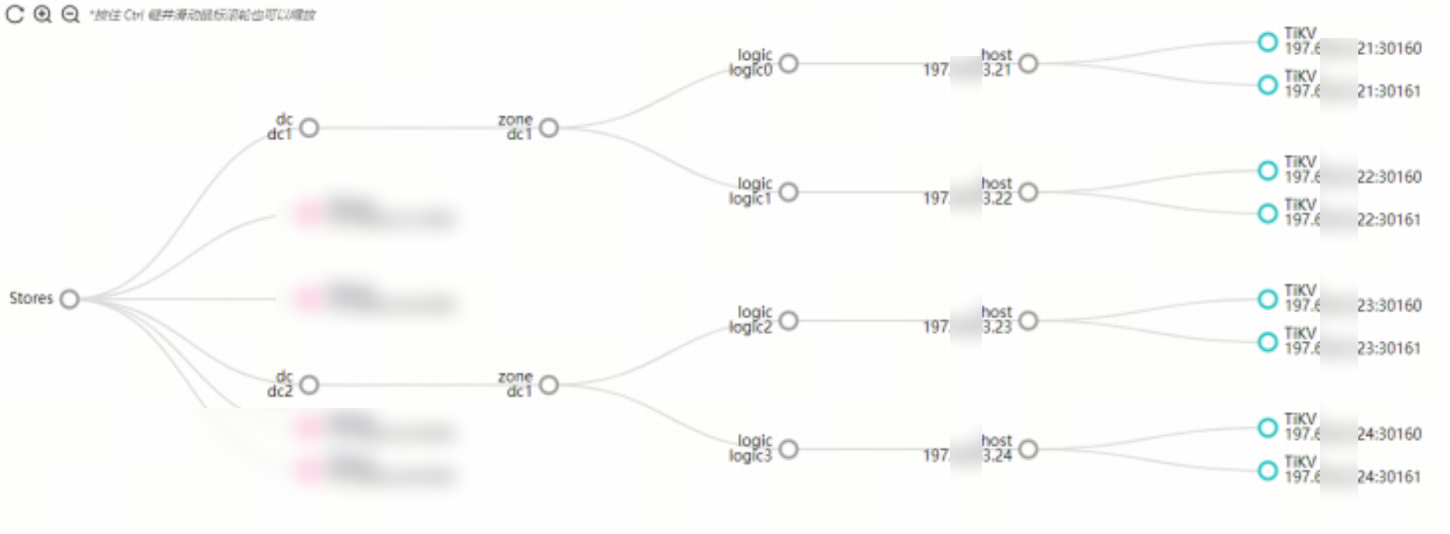
在启用 Placement Rules 的集群中,可以通过配置 rules.json 对 TiKV 的数据进行全局数据副本和副本标签的关联控制。
- 将所有配置保存至
rules.json文件。
pd-ctl config placement-rules rule-bundle load --out="rules.json"
- 配置
rules.json文件。
参考 https://docs.pingcap.com/tidb/stable/configure-placement-rules/#scenario-2-place-five-replicas-in-three-data-centers-in-the-proportion-of-221-and-the-leader-should-not-be-in-the-third-data-center 的样例文件进行修改,定义所需的副本拓扑。
从例子中可以看到,"label_constraints": [{"key": "zone", "op": "in", "values": ["zone1"]} 代表节点标签具备的特征,"role": "voter", "count": 2 代表数据副本的特征,voter 代表正常的数据副本(不限制是 leader 或者 follower)。
具体字段说明参考 https://docs.pingcap.com/zh/tidb/stable/configure-placement-rules/#%E8%A7%84%E5%88%99%E5%AD%97%E6%AE%B5
- 编辑完文件后,使用下面的命令将配置保存至 PD 服务器:
pd-ctl config placement-rules rule-bundle save --in="rules.json"
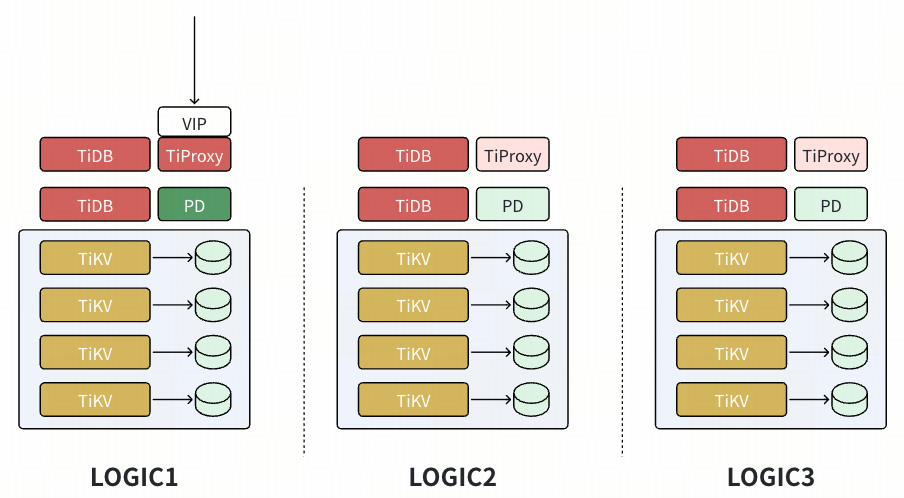
基于 Placement Rules 将副本数量从 3 个扩展到 5 个
- 配置 placement rules,在 Logic1~Logic3 上各有 1 voter。

- 扩容新节点(配置有新的 Logic 标签),由于当前的规则是在 Logic1~Logic3 上各有 1 voter,所有新节点上并不会有数据调度产生。新增配置 placement rules,在 Logic4~Logic5 上各有 1 Learner,开始有数据副本注入新节点,但是此时新数据节点仅为 Learner,触发 Compaction 等操作也不影响生产 SQL。对生产影响仅为 Leader 发送数据副本给新节点,影响可控。
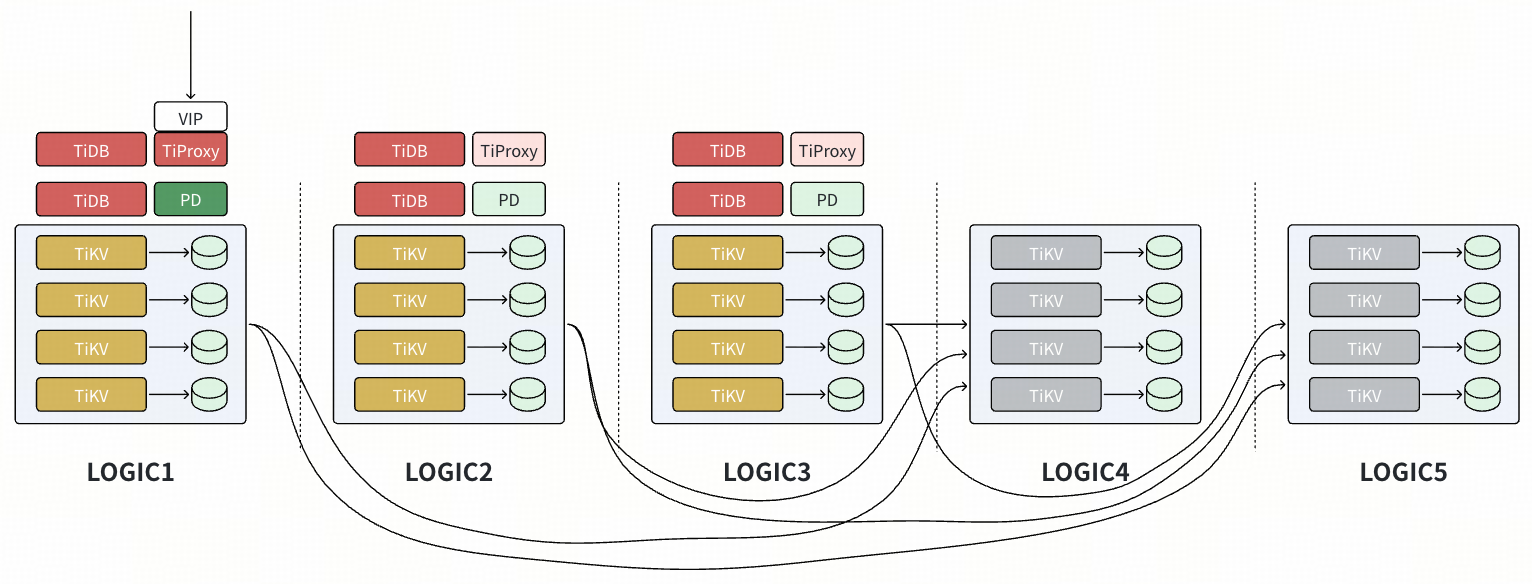
- 配置 placement rules,修改为在 Logic1~Logic5 上各有 1 voter,对生产影响仅为轻量的 Leader 调度。
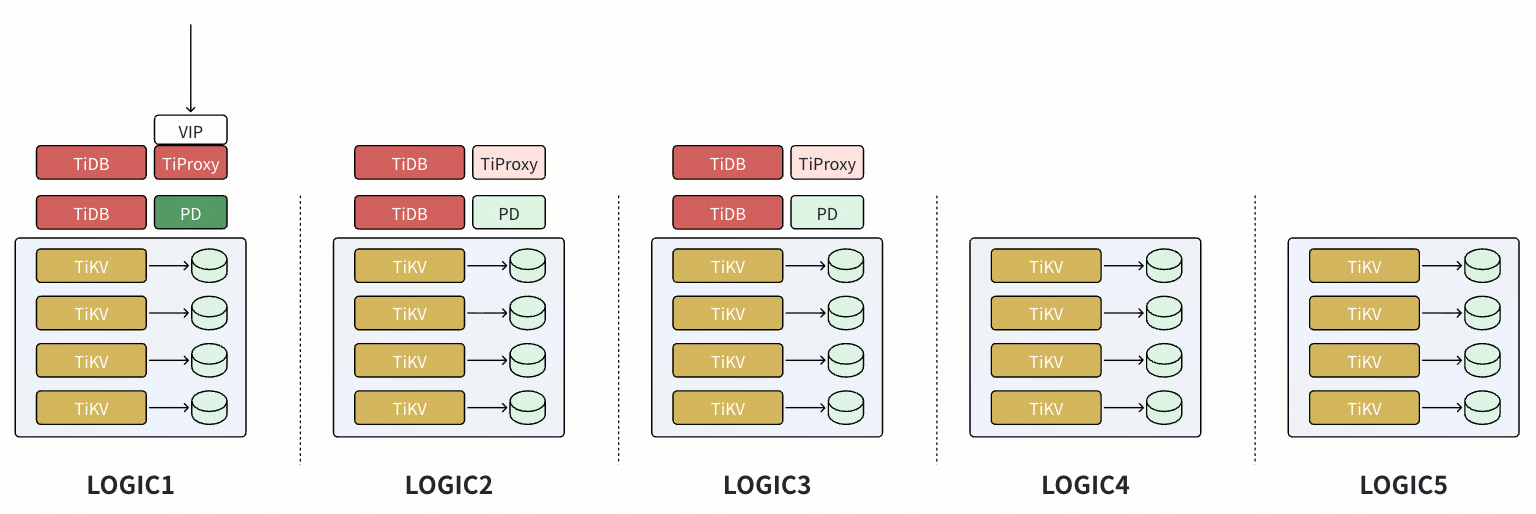
基于 Placement Rules 进行节点替换(搬迁或者节点下线场景)
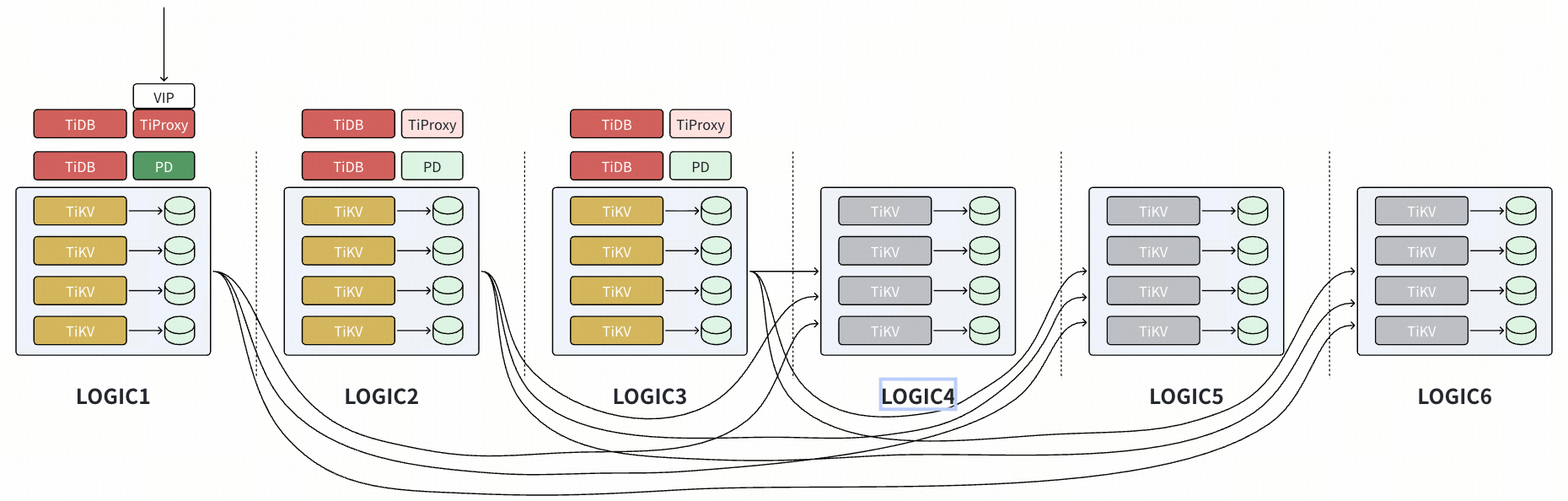
- 配置 placement rules,在 Logic1~Logic3 上各有 1 voter。
- 扩容新节点(配置有新的 Logic 标签),由于当前的规则是在 Logic1~Logic3 上各有 1 voter,所有新节点上并不会有数据调度产生。新增配置 placement rules,在 Logic4~Logic6 上各有 1 Learner,开始有数据副本注入新节点,但是此时新数据节点仅为 Learner,触发 Compaction 等操作也不影响生产 SQL。对生产影响仅为 Leader 发送数据副本给新节点,影响可控。
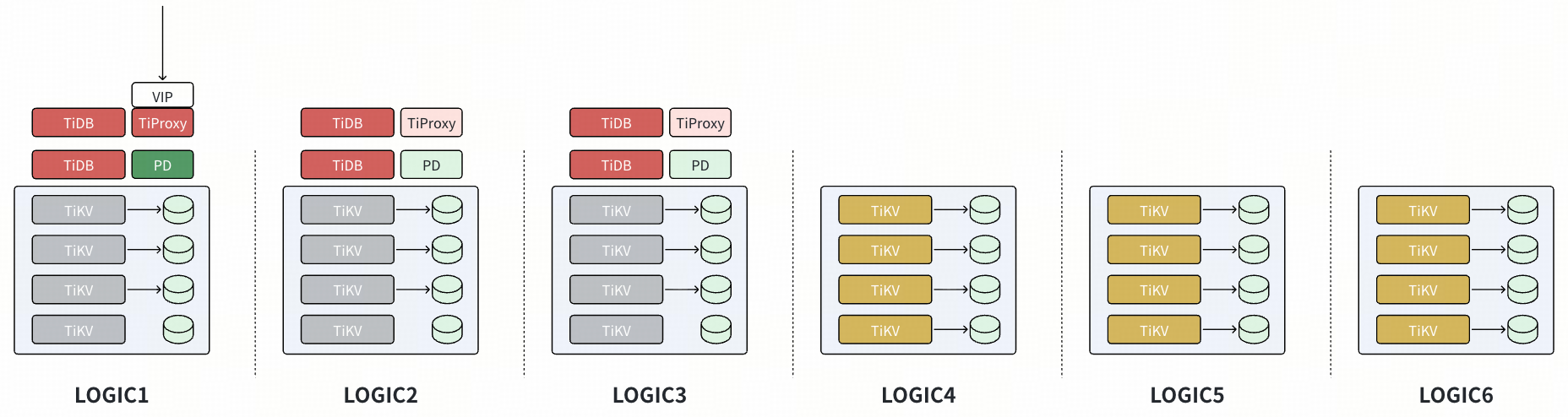
- 等 Region 平衡后,配置 placement rules,在 Logic4~Logic6 上有 voter,在 Logic1~Logic3 上有 learner。由于数据副本已经就绪,不涉及数据的平衡操作,对生产影响仅为轻量的 Leader 调度,影响可控。
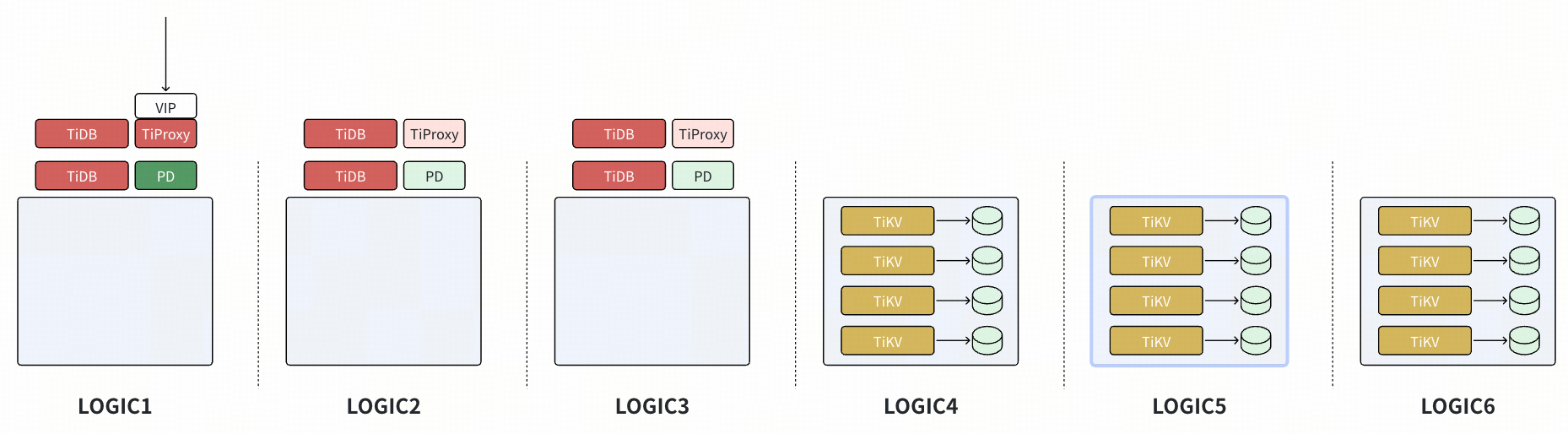
- 配置 placement rules,仅在 Logic4~Logic6 的 TiKV 有 voter。等 Logic1~Logic3 的 TiKV 节点完成 learner 副本下线后,对 TiKV 进行缩容,过程对生产没有影响。
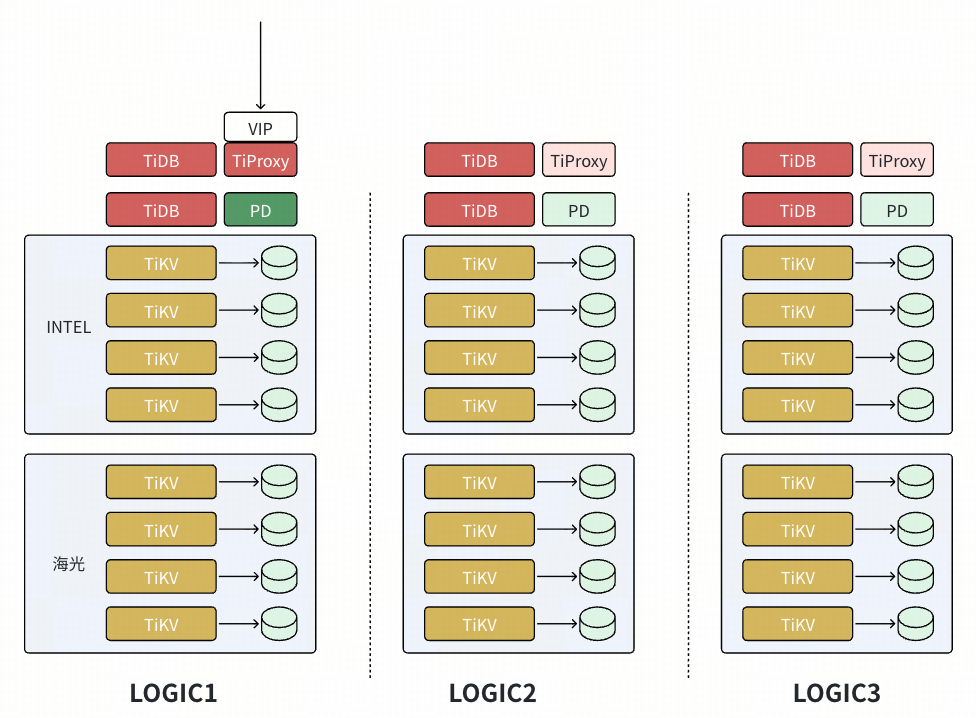
基于 Placement Rules 进行集群节点的扩展(3 台 Intel 节点扩展3 台海光节点)
- 配置 placement rules,仅在 Logic2 / Logic 3 上有 Leader,Logic 1 为 Follower 角色,过程中对生产影响为轻量的 Leader 调度。
注意:Follower 角色节点不响应 TiDB 的 IO 请求,尤其是不参加 Coprocessor 的下推计算,需要关注最初各个节点的负载,能否满足一台节点的冗余需求。
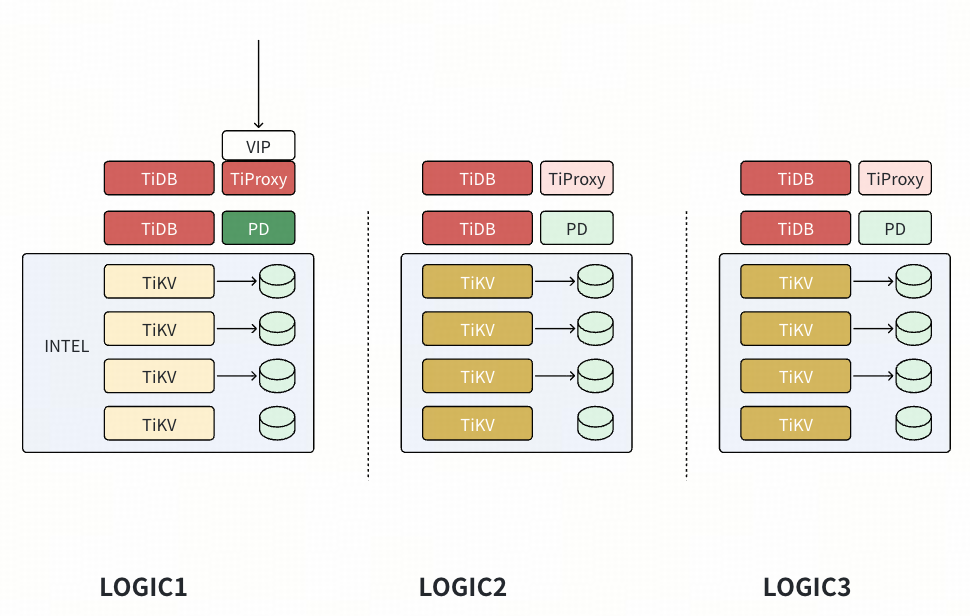
- 扩容新节点(配置有原来的 Logic 标签),由于两台节点的容量占用不平衡,开始有数据副本迁入新节点,Logic 1 的原节点会删除多余的 Peer。此时 Logic1 的节点都是 Follower,触发 Compaction 等操作也不影响生产 SQL。对生产影响仅为 Leader 发送数据副本给新节点,影响可控。
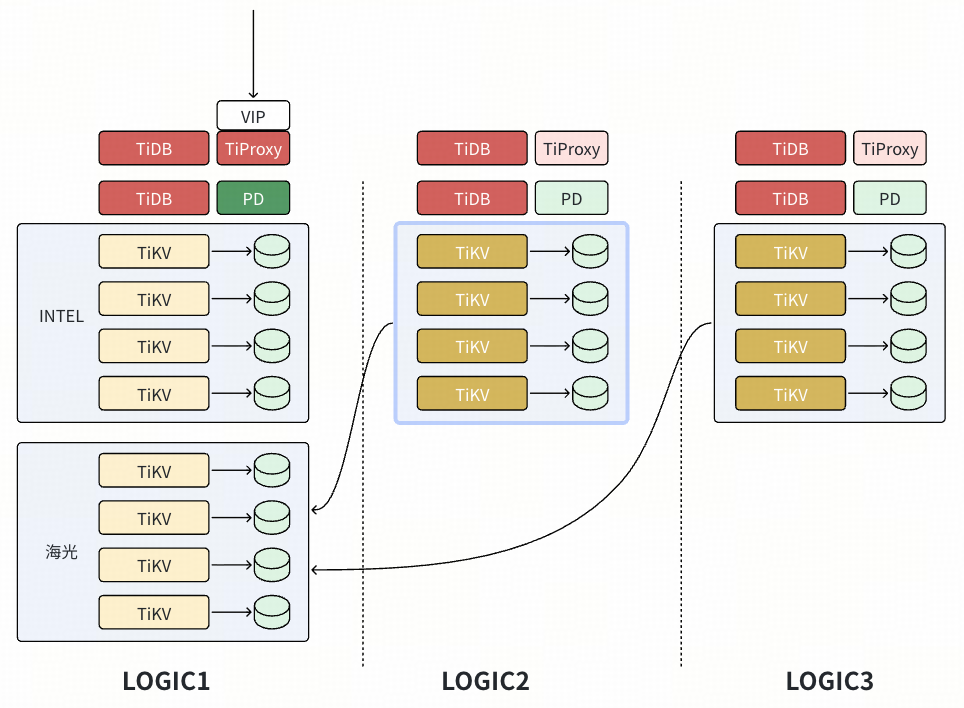
- 等 Logic 1 的节点扩容的数据重平衡完成后,扩容 Logic 2 新节点(配置有原来的 Logic 标签),角色切换和调度过程和步骤 1 和 2 一致。完成 Logic 2 的节点迁移后,再完成 Logic 3 的节点迁移。
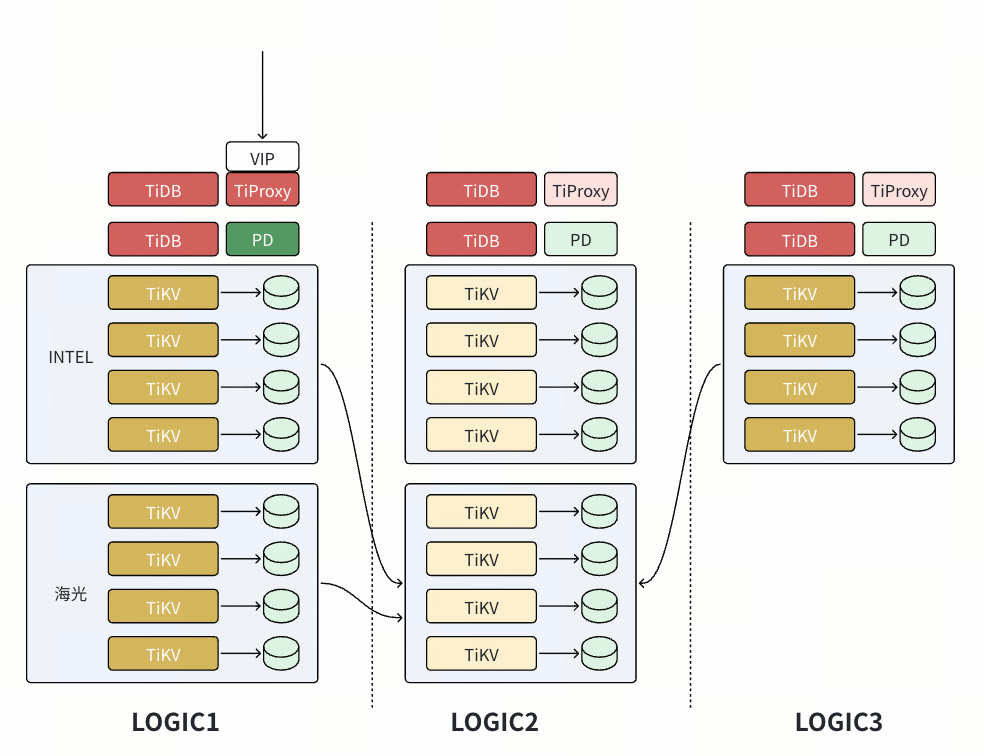
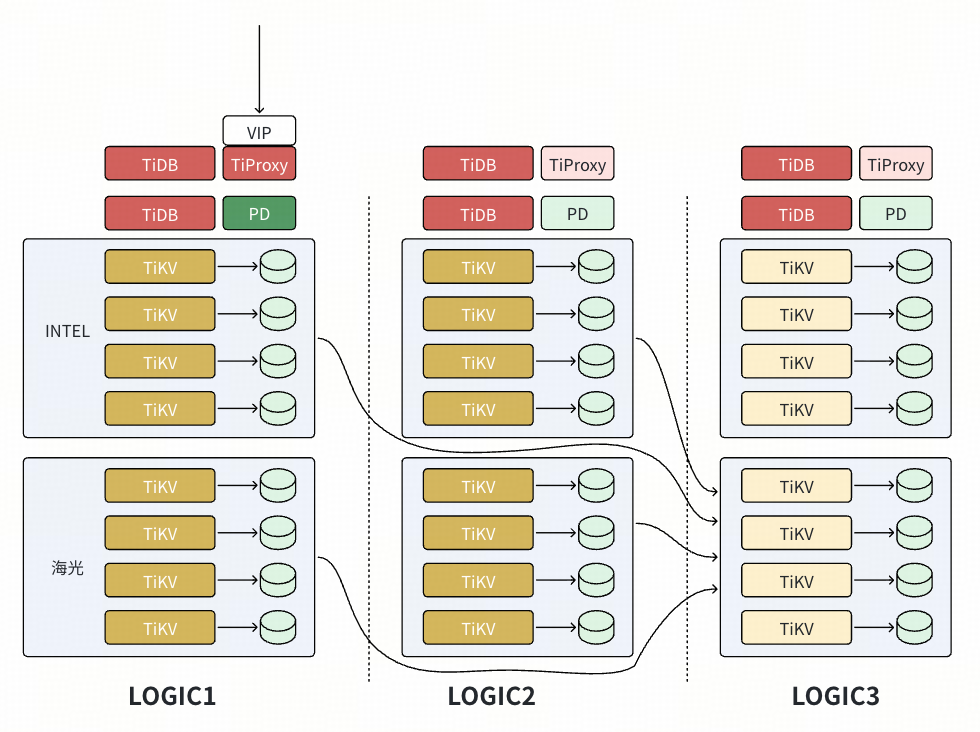
- 等 Logic 3 的节点扩容的数据重平衡完成后,恢复默认的 placement rules。
小结
从以上几个例子中可以看出,用 Placement rules 控制扩缩容过程的总体思路主要有几项:
- 将 Leader 角色的数据副本约束在不进行数据副本调整的节点上,防止节点上有磁盘 I/O、CPU 和网络资源用于数据副本的调整,导致 Leader 角色的数据副本服务质量下降,造成生产的影响。
- 由于 Learner / Follower 不服务于生产,扩缩容过程中实际在进行数据副本调整的节点配置 Learner / Follower 角色,规避数据重平衡过程造成生产的影响。
- 在业务低峰窗口或者通过调度参数,避免 Leader 调度对业务的影响。
操作过程的注意项:注意经常使用 pd-ctl 和 jq 命令的组合查看副本分布是否符合要求,查看 PD 的 operator 面板的调度是否符合预期。
- 集群Placememt rule 角色转换涉及3类operator:fix-peer-role learner转voter,fix-follower-role voter转follower,fix-demote-role voter/follower转learner
- Pd生成operator 的顺序由placement rule 配置[groupindex,groupID,index,ID]排序决定,例如rule1 [groupindex:1,groupID:1,index:0,ID:1], rule2 [groupindex:1,groupID:1,index:1,ID:1]。由于两个rule的groupindex,groupID相同继续比较index,rule1 index:0<rule2 index:1,优先执行rule1的角色转换
附: Raft 角色说明
在 TiKV 的 Raft 共识机制中,数据副本的角色设计是为了在保证数据强一致性的前提下,兼顾系统的高可用性与扩展性。这些角色主要分为参与投票的 Voter(包含 Leader 和 Follower)和不参与投票的 Learner。
以下是这三个核心角色的详细说明:
Leader(领导者)—— 核心处理者
Leader 是 Raft 集群中唯一能处理客户端写请求的角色,是数据一致性的“源头”。
-
核心职责:
- 处理写请求:所有客户端的写请求(Put/Delete)都必须发送给 Leader。Leader 将请求转化为日志条目(Log Entry)。
- 日志复制:Leader 负责将日志条目通过
AppendEntriesRPC 并行发送给所有的 Follower 和 Learner。 - 提交事务:当日志被大多数(Quorum) Voter 节点(包括 Leader 自己和 Follower)成功接收并持久化后,Leader 会将该日志标记为“已提交”(Committed),并应用到状态机,最后向客户端返回成功。
- 心跳维持:Leader 定期向其他节点发送心跳,以维持其领导地位,防止 Follower 发起选举。
-
数量限制:在一个 Raft Group(即 TiKV 中的一个 Region)中,同一时刻只能有一个 Leader。
Follower(追随者)—— 投票者与备份
Follower 是 Raft 集群中的“选民”和数据备份节点,它们被动地接收 Leader 的指令,但在选举和日志提交中起决定性作用。
-
核心职责:
- 被动接收:Follower 不直接处理客户端的写请求,而是被动接收 Leader 发送的日志条目和心跳。
- 参与投票(Voter):Follower 拥有投票权。当集群启动或 Leader 故障(心跳超时)时,Follower 会转换为 Candidate(候选人)发起选举,或者对 Candidate 的投票请求进行响应。
- 计入法定人数(Quorum):在日志提交阶段,Leader 必须收到包括 Follower 在内的“大多数”节点的确认才能提交日志。因此,Follower 的响应速度直接影响写入延迟。
- 处理读请求:Follower 可以处理线性化读请求(需与 Leader 确认)或旧读(Stale Read,直接读取本地数据)。
-
关键特性:Follower 是保证数据高可用和强一致性的基石。如果 Follower 宕机,只要数量未超过半数,集群仍可正常工作;但如果 Follower 响应过慢,会拖累 Leader 的提交速度。
Learner(学习者)—— 旁观者与扩展者
Learner 是 Raft 协议的一种扩展角色(在 TiFlash/TiKV 中广泛使用),它只同步数据但不参与“政治”活动(选举和投票)。
-
核心职责:
- 异步同步:Learner 接收 Leader 发送的日志流,保持数据的实时同步。
- 不参与投票:Learner 没有投票权,也不参与 Leader 选举。
- 不计入 Quorum:Leader 在提交日志时,不需要等待 Learner 的确认。这意味着 Learner 的故障或高负载完全不会影响主链路的写入性能和延迟。
-
应用场景:
- 节点扩缩容:新加入的节点通常先以 Learner 身份加入,快速追赶数据。当数据同步完成后,再晋升为 Follower。这样可以避免新节点在数据同步期间因缺票导致集群不可用。
- HTAP 分离(TiFlash):在 TiDB 的 HTAP 架构中,TiFlash 节点就是以 Learner 身份加入 Raft 组的。它实时同步数据用于分析查询(OLAP),但因其负载较重,如果不将其设为 Learner,分析查询的抖动会直接拖慢在线交易(OLTP)的写入速度。
- 异地容灾/备份:可以部署 Learner 在远距离的机房用于容灾备份,因为它不阻塞主集群的写入确认。