

PCTA学习笔记,依据官方文档和官方提供的视频进行整理的。
今天学习,TiDB数据库的架构,Lesson 04
官方文档:https://pingkai.cn/docs/tidb/stable/tidb-computing
PCTA必学课程:101-TiDB 数据库核心原理与架构:https://learn.pingkai.cn/learner/course/1290025
一、Module 01:TiDB数据库架构
1 Lesson 04: PD (Placement Driver)
1.1 PD 的架构
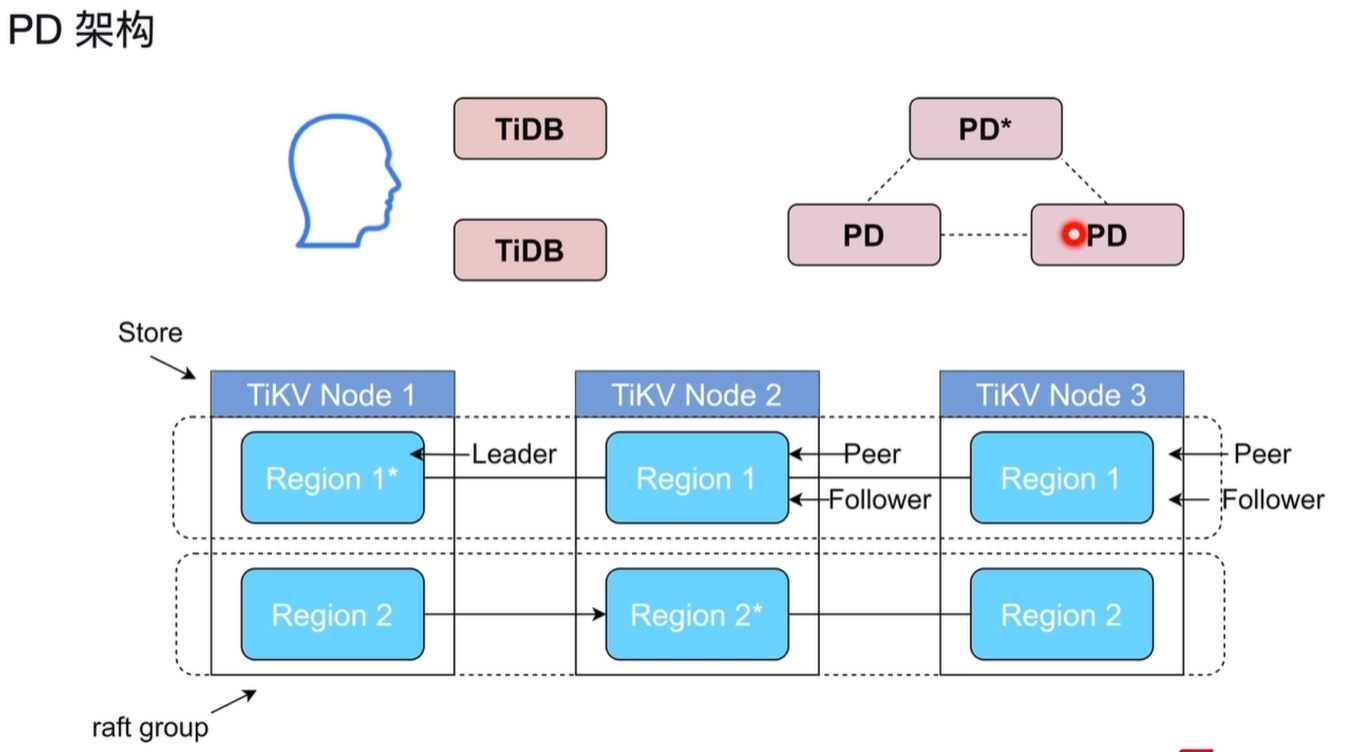
1.1.1 组件角色与功能
1)PD (Placement Driver) 集群
- 元数据管理:整个集群的“大脑”,存储集群的元数据,如 Region 的分布、拓扑信息。
- 调度中心:负责 TiKV 节点间的负载均衡、Region 分裂/合并、Raft 组 Leader 调度。
- 分布式一致性:自身通过 Raft 协议组成集群,保证 PD 元数据的高可用,图中标
*的为 Leader 节点。 - 全局时间戳( TSO)分配:为分布式事务分配全局单调递增的时间戳,支持多版本并发控制(MVCC)。
- PD 默认部署 3 个节点,构成一个高可用集群
2)TiKV 存储集群
-
数据持久化层:负责实际数据的存储,采用 Key-Value 引擎。
-
Region 数据分片:
- 数据按 Key 范围被切分为多个 Region(默认 96MB)。
- 每个 Region 是一个 Raft Group,包含 3 个副本(Leader + 多个 Follower),分布在不同 TiKV 节点上。
Leader:处理读写请求,与 Follower 同步日志。Follower:被动同步数据,故障时可被选举为 Leader。
-
Peer :
- Peer:Region 的副本也被称为 Peer。
- 每个 Region 默认包含 3 个 Peer(副本),分布在不同的 TiKV 节点上,通过 Raft 协议保证数据一致性。
- 其中一个 Peer 为 Leader,负责处理读写请求;其余为 Follower,被动同步数据,故障时可被选举为新的 Leader。
-
Store:每个 TiKV 节点就是一个 Store,承载多个 Region 副本。
1.1.2 架构工作流程
- 用户请求:客户端连接 TiDB Server,发送 SQL 请求。
- 路由查询:TiDB Server 向 PD 查询所需数据所在的 Region Leader 位置。
- 读写操作:TiDB 直接与对应的 TiKV 节点上的 Region Leader 交互,执行读写操作。
- 副本同步:Region Leader 通过 Raft 协议将日志同步给 Follower,保证数据一致性。
- PD 调度:PD 持续监控集群状态,自动调整 Region 分布、负载均衡和故障恢复。
1.1.3 关键特性
- 水平扩展:TiDB、TiKV、PD 均可按需扩展。
- 高可用:Region 三副本 + PD 集群保证服务不中断。
- 强一致性:基于 Raft 协议实现数据的强一致性。
- 自动负载均衡:PD 自动调度 Region,实现数据和读写负载的均衡分布。
1.2 PD主要功能

PD 是 TiDB 集群的元数据管理和全局调度中心,核心功能包括:
- 整个集群 TiKV 的元数据存储 记录所有 TiKV 节点、Region 分布、副本位置等关键信息,是 TiDB 查询数据路由的依据。
- 分配全局 ID 和事务 ID 为集群中的数据对象(如表、索引)和事务提供全局唯一的 ID,保证分布式环境下的标识唯一性。
- 生成全局时间戳 TSO 提供全局单调递增的时间戳服务,用于分布式事务的 MVCC(多版本并发控制),保障事务一致性。
- 收集集群信息进行调度 持续监控 TiKV 节点状态、负载情况,自动进行 Region 分裂/合并、负载均衡、故障恢复等调度操作。
- 提供 Label,支持高可用 通过节点 Label 实现机房、机架级别的副本分布策略,例如跨机房部署,提升集群容灾能力。
- 提供 TiDB Dashboard 内置集群监控面板,提供节点状态、Region 分布、性能指标、慢查询等可视化监控功能。
1.3 路由功能
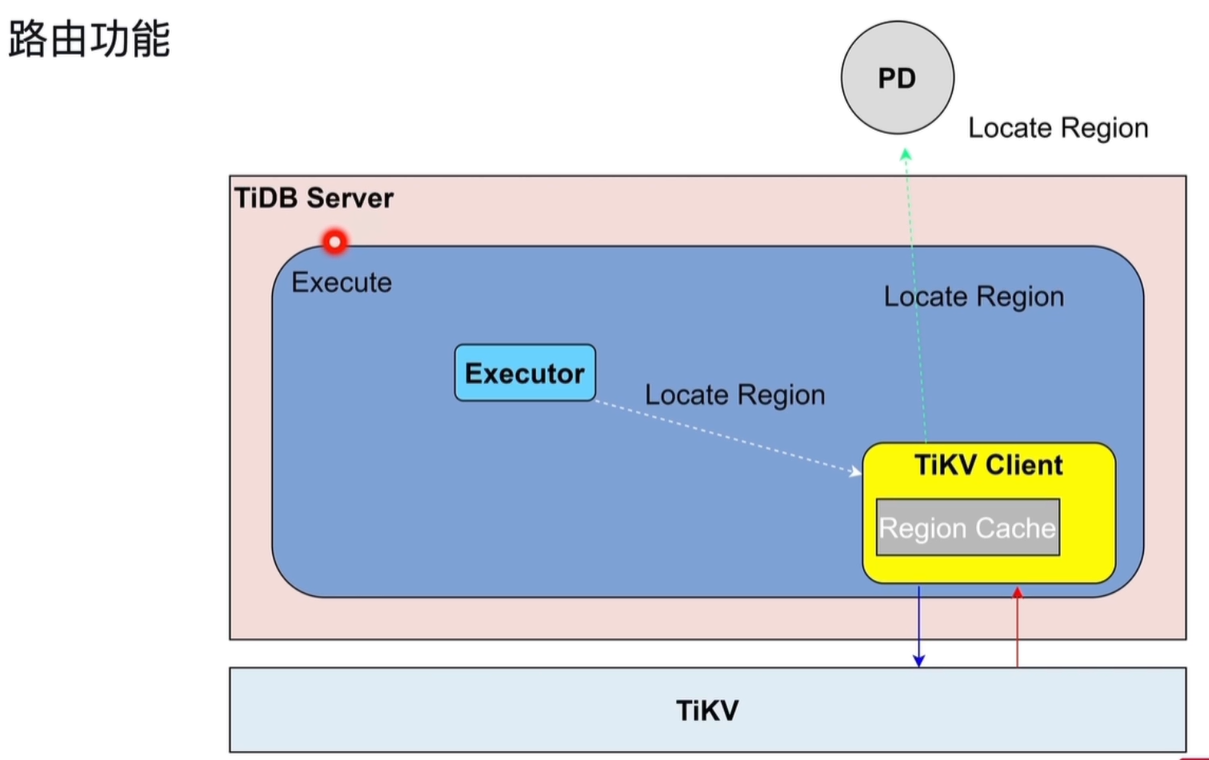
1.2.1 核心组件
- TiDB Server:SQL 层入口,包含 Executor 执行器和 TiKV Client 客户端
- TiKV Client:内嵌在 TiDB 中的客户端,负责与 TiKV 通信,内部维护
Region Cache - Region Cache:缓存 Key 到 Region Leader 的路由信息,是路由功能的关键,无需每次都向 PD 发起查询,大幅降低路由开销。
- PD (Placement Driver):集群元数据中心,存储所有 Region 的分布信息
- TiKV:数据存储层,实际存放 Region 数据
1.2.2 路由流程
-
SQL 执行请求 用户发送 SQL 后,
Executor执行计划需要访问具体数据,会向TiKV Client发起请求。 -
本地缓存查询
TiKV Client首先在Region Cache中查找 Key 对应的 Region 及其 Leader 节点位置。- 命中:直接向对应的 TiKV 节点发送读写请求(蓝色箭头)
- 未命中/缓存失效:向 PD 发起
Locate Region请求(绿色虚线箭头)
-
PD 元数据查询 PD 返回该 Key 所在的 Region 信息及当前 Leader 节点地址。
-
更新缓存并访问
TiKV Client更新Region Cache,然后向目标 TiKV 节点发送读写请求(蓝色箭头)。 -
TiKV 响应 TiKV 节点处理请求后,将结果返回给
TiKV Client,再由 TiDB 整理返回给用户(红色箭头)。
1.2.3 关键机制说明
-
Region Cache 作用: 避免每次请求都查询 PD,大幅提升路由性能,是 TiDB 高性能的关键优化。
-
缓存更新时机:
- 首次访问 Key
- Region 发生分裂/合并
- Region Leader 发生迁移 这些场景下缓存会失效,TiKV Client 会重新向 PD 查询并更新缓存。
1.4 TSO的分配
1.4.1 TSO的分配
-
TSO(physical time logical time) = 物理时间 + 逻辑时间
- 高位:真实物理时间
- 低位:逻辑时间,1毫秒可拆分出262144个TSO
-
存储类型:int64整型
1.4.2 TSO分配过程
- 触发时机 SQL执行初始阶段申请TSO,事务开启、提交阶段均会发起TSO请求。
- 执行时序 节点4、5操作存在先后等待关系;2与4、3与5两组流程异步并行执行。
- 批量请求优化 SQL并发量大、TSO请求频繁,PD Client不会单次单请求上报。 设定时间阈值(如5毫秒),周期内积攒所有请求后批量统一提交至PD;周期内仅单个请求也正常发起上报。
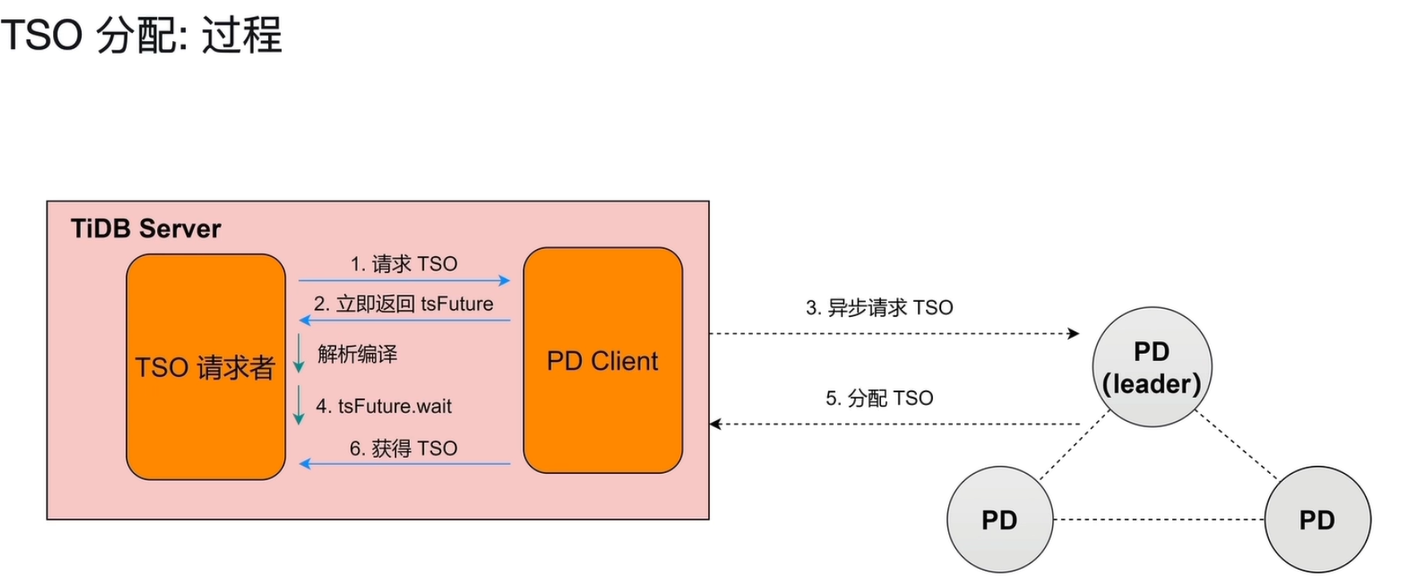
1) 核心组件
- TSO 请求者:TiDB Server 中需要获取全局时间戳的模块(如事务模块)
- PD Client:TiDB Server 内嵌的 PD 客户端,负责与 PD Leader 通信
- PD (Leader):集群中负责生成全局 TSO 的主节点,通过 Raft 协议保证高可用
2)分配流程
- 发起请求:TSO 请求者向 PD Client 发起获取 TSO 的请求。
- 异步 Future 返回:PD Client 立即返回一个
tsFuture对象,请求者无需阻塞等待。 - 后台异步请求:PD Client 在后台向 PD Leader 发起 TSO 请求。
- 业务并行处理:在等待 PD 响应的同时,TSO 请求者可以继续执行 SQL 的解析、编译等任务。
- PD 分配 TSO:PD Leader 收到请求后,生成全局唯一且单调递增的时间戳,返回给 PD Client。
- 获取 TSO:PD Client 收到响应后,将结果填入
tsFuture。请求者通过tsFuture.wait()获取最终的 TSO。
3)关键优化点
- 异步请求 + Future 模式:通过异步请求和
Future对象,将 TSO 获取过程与 SQL 解析编译并行化,有效降低了 TSO 调用的延迟。 - PD Leader 高可用:PD 集群通过 Raft 协议保证 TSO 服务的高可用,主节点故障时可快速切换,不影响服务。
1.4.3 TSO分配:时间窗口
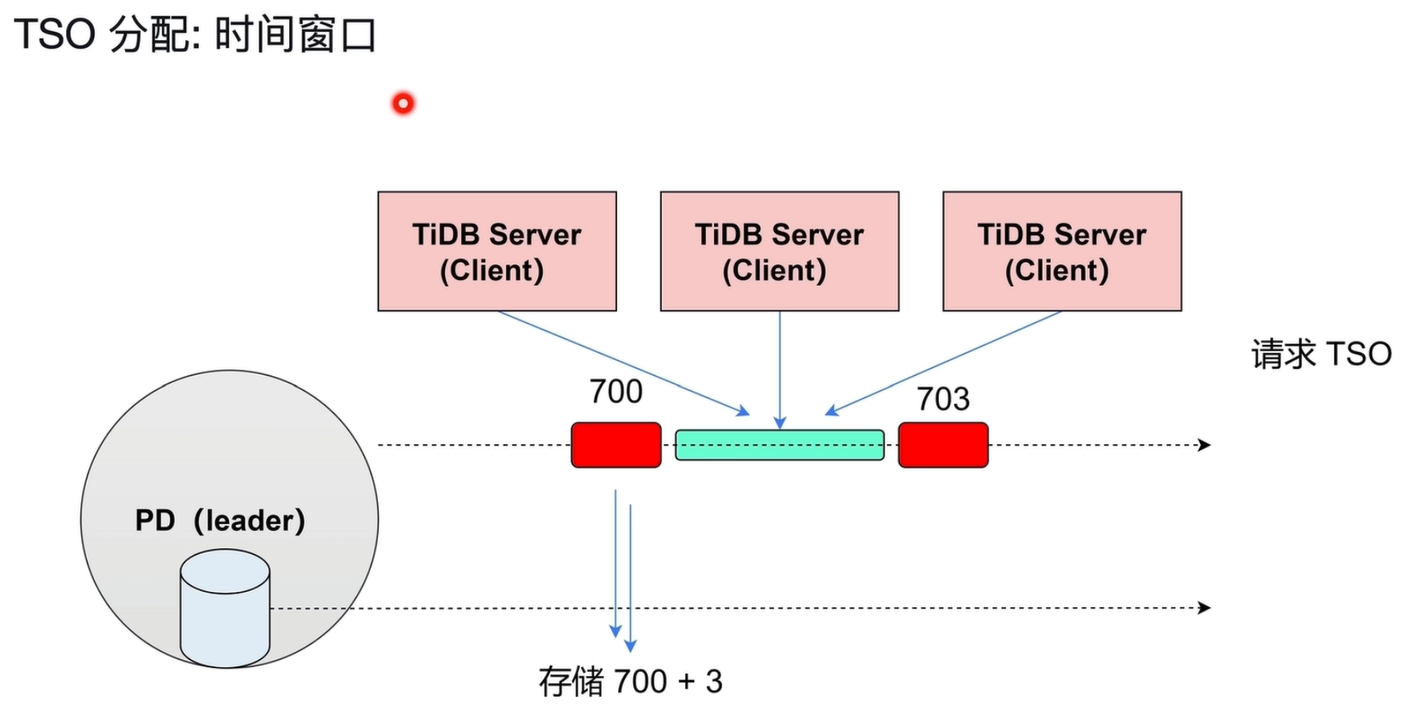
1)性能瓶颈解决
TiDB Server 会持续发送大量 TSO 请求,若每个请求都直接落地到 PD 持久化存储,会产生频繁磁盘 IO,影响系统吞吐量,PD Leader 为了提升 TSO 分配的吞吐量(解决性能瓶颈),会采用批量分配时间窗口的优化方式,而不是每个请求都单独处理。
- 批量预分配:PD Leader 一次性分配一段较长时间窗口内的 TSO(如 3 秒),缓存到内存中供 TiDB Server 使用。
- 队列消费:TiDB Server 的请求按顺序从 PD 的缓存中获取 TSO,无需每次都访问磁盘。
- 周期更新:当缓存中的 TSO 即将耗尽时,PD 再批量向磁盘写入新的 TSO 区间(如从 703 更新到 706),将磁盘 IO 频率降低到 3 秒 1 次。
2)PD Server 高可用与故障恢复
-
状态同步:Leader 分配的 TSO 区间(如 703-706)会通过 Raft 协议同步给所有 Follower PD 节点,保证集群状态一致。
-
Leader 故障场景:
- 假设原 Leader 在缓存中分配到 704 时宕机,此时磁盘中已同步的最大分配记录是 706。
- 新的 Leader 节点无法感知原 Leader 内存中已分配到 704 的状态,只会基于磁盘记录的最大值 706,继续分配新的区间 706-709。
-
关键结论:
- 这种机制能严格保证 TSO 的全局唯一性,不会出现重复,满足分布式事务的核心要求。
- 但无法保证 TSO 的连续性,上述场景中 704-705 这两个序号会永久丢失,形成空洞。
3)工作流程(结合图中示例)
-
批量请求:多个 TiDB 客户端同时向 PD 发送 TSO 请求。
-
时间窗口分配:PD 收到请求后,不是逐个处理,而是为这一批请求分配一个连续的时间窗口。
- 例如,PD 当前时间戳为
700,为这 3 个请求分配了从700到703的时间窗口。
- 例如,PD 当前时间戳为
-
原子性更新:PD 将时间窗口的起始值
700和数量3写入持久化存储,然后一次性返回给所有客户端。 -
客户端获取 TSO:每个客户端根据请求在批次中的顺序,从时间窗口中拿到自己的 TSO(如
700、701、702)。
4)优化效果
- 降低请求开销:多个客户端请求只需要一次 PD 处理和一次持久化操作,大幅提升了 TSO 服务的吞吐量。
- 保证全局有序:时间窗口内的 TSO 依然是全局单调递增的,不会出现重复或回退。
1.5 PD的调度原理
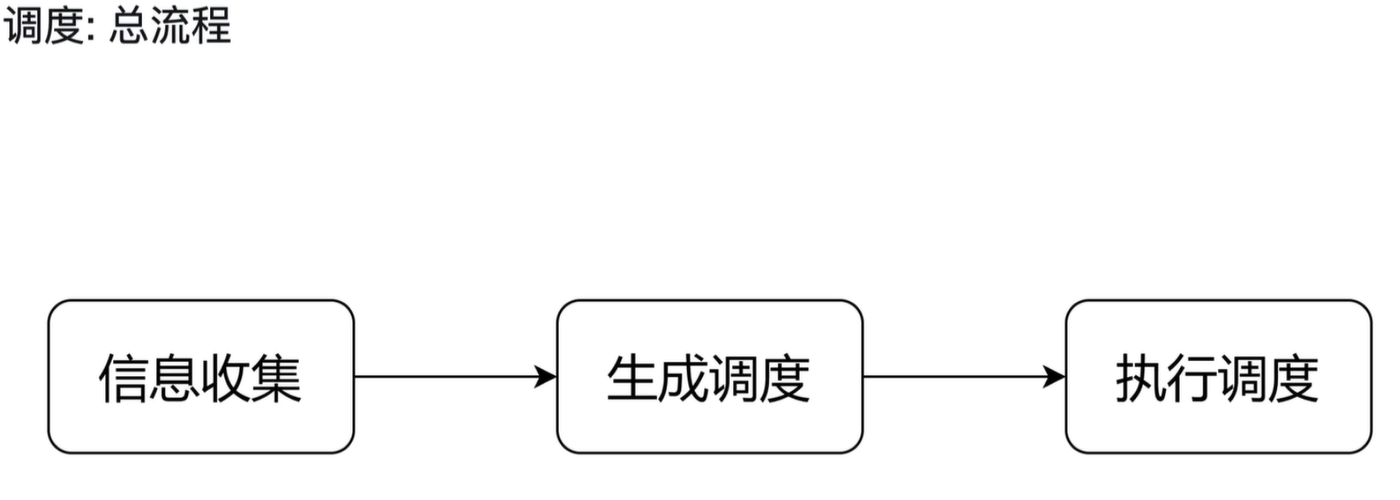
1.5.1 PD 调度:总流程
1) 流程概述
PD 的调度过程分为三个核心阶段:信息收集 → 生成调度 → 执行调度。
2)阶段详解
-
信息收集 PD 持续从所有 TiKV 节点采集关键信息,包括:
- 节点状态(在线/离线、负载情况)
- Region 分布与副本状态
- 磁盘使用、读写流量等指标 这些数据是后续调度决策的基础。
-
生成调度 PD 根据预设的调度策略和收集到的信息,分析集群当前是否存在问题,例如:
- 节点负载不均(热点 Region)
- 副本分布不符合高可用策略(如同机房副本过多)
- 节点故障导致副本缺失 PD 会生成对应的调度算子(如 Region 迁移、Leader 转移、副本添加/删除)。
-
执行调度 PD 将生成的调度指令下发给目标 TiKV 节点执行,例如:
- 指示某 TiKV 将一个 Region 的副本迁移到另一个节点
- 指示某 TiKV 将一个 Region 的 Leader 角色转移给其 Follower 执行过程中,PD 会监控状态,确保调度成功完成。
1.5.2 PD 调度:信息收集
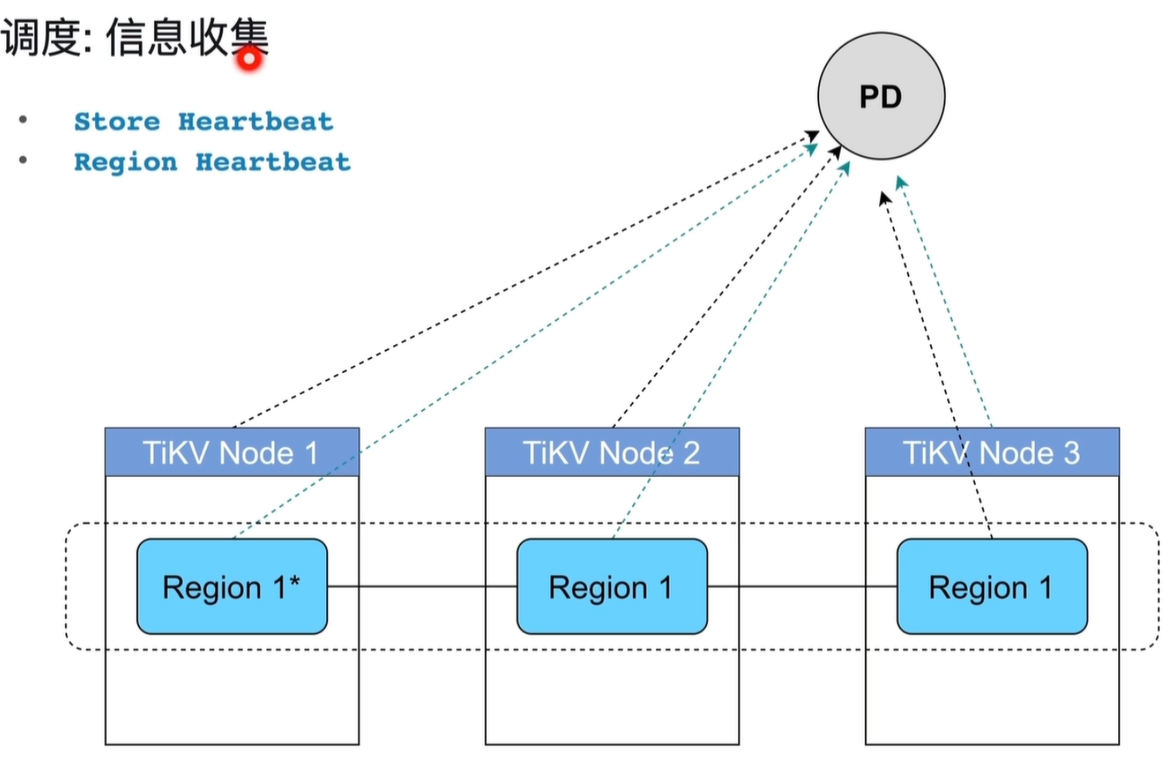
1) 核心机制
PD 通过两类心跳机制,从 TiKV 节点持续收集集群状态数据,为后续调度提供依据。
2) 两类心跳
-
Store Heartbeat(节点心跳)
-
由每个 TiKV 节点定期向 PD 发送。
-
上报节点级别的状态信息,如:
- 节点在线状态
- 磁盘容量、使用情况
- CPU、内存、读写负载
- 节点标签(Label)信息
-
作用:让 PD 了解每个节点的健康状况和负载能力。
-
-
Region Heartbeat(Region 心跳)
-
由每个 Region 的 Leader 副本定期向 PD 发送。
-
上报 Region 级别的状态信息,如:
- Region 当前的 Leader、Follower 分布位置
- Region 的数据大小、读写流量
- 副本健康状态(是否同步)
-
作用:让 PD 掌握每个数据分片的分布和状态,是 Region 调度的基础。
-
3)工作流程
- 每个 TiKV 节点会同时发送
Store Heartbeat和其所有 Leader Region 的Region Heartbeat给 PD。 - PD 汇总这些信息,构建出整个集群的实时状态视图。
- 后续的调度决策(如负载均衡、故障恢复)都基于这些心跳数据生成。
1.5.3 PD 调度:生成调度

1)调度策略分类
PD 根据收集到的集群信息,会生成多种类型的调度任务,主要包括以下几类:
2)3.8.2 各类调度策略详解
-
Balance(负载均衡)
- Leader Balance:将 Region 的 Leader 副本均匀分布到各个 TiKV 节点,平衡节点的读写负载。
- Region Balance:将 Region 副本均匀分布,平衡节点的磁盘存储和数据分布。
-
Hot Region(热点 Region 调度)
- 识别读写压力过大的热点 Region,通过迁移 Leader 或副本,将负载分散到其他节点,避免单节点瓶颈。
-
集群拓扑调度
- 根据节点的标签(如机房、机架),调整副本分布,确保副本跨机房/机架部署,提升集群容灾能力。
-
缩容调度
- 当需要下线 TiKV 节点时,自动将该节点上的所有 Region 副本迁移到其他节点,确保数据安全,实现平滑缩容。
-
故障恢复调度
- 当节点宕机或副本丢失时,自动生成调度任务,补充副本或重新选举 Leader,确保副本数符合配置要求,维持集群高可用。
-
Region merge(Region 合并)
- 将多个连续的小 Region 合并为一个大 Region,减少元数据开销和调度压力,提升整体性能。
1.5.4 PD 调度:执行调度

1)核心流程
PD 生成调度任务后,会通过下发 operator 的方式,驱动 TiKV 节点完成实际的调度动作。
2)调度执行过程
-
下发 Operator PD 将生成的调度指令(Operator)发送给目标 TiKV 节点,如图中所示,PD 向
TiKV Node 1下发指令。-
Operator 描述了具体的调度动作,如:
- 将某个 Region 的 Leader 迁移到指定节点
- 为某个 Region 添加/删除副本
- 合并/分裂 Region
-
-
TiKV 执行调度 TiKV 节点收到 Operator 后,会执行相应的操作:
- Leader 迁移:将 Region 的 Leader 角色转移到指定节点。
- 副本迁移:将 Region 数据从当前节点复制到目标节点,同步完成后删除本地副本。
- 故障恢复:补充缺失的副本,确保副本数符合配置。
-
状态反馈 调度执行过程中,TiKV 会通过心跳机制向 PD 报告进度和状态。PD 监控调度过程,若执行失败会进行重试或调整策略。
3)关键特点
- 异步执行:PD 下发指令后无需等待,调度在 TiKV 节点后台异步执行,不影响集群业务。
- 安全可靠:所有调度动作都基于 Raft 协议保证数据一致性,迁移过程中不影响服务可用性。
1.6 label的作用
1.6.1 label 和高可用性
-
层级定义:DC代表独立数据中心,RACK代表机柜,TiKV代表物理主机。
- Region 1风险:3副本中有2个集中在同一机柜(如Rack4),当该机柜或所属数据中心(DC2)故障时,2个副本同时失效,仅剩1个副本,不满足多数派要求,集群无法正常读写。
- Region 2风险:副本集中部署在同一数据中心(DC1),当该数据中心整体故障时,所有副本同时失效,数据完全不可用。
- Region 3最优实践:副本分布在独立的DC、RACK和TiKV节点中,单个数据中心、机柜或主机故障时,最多仅损失1个副本,剩余副本仍能满足多数派要求,稳定性最高。
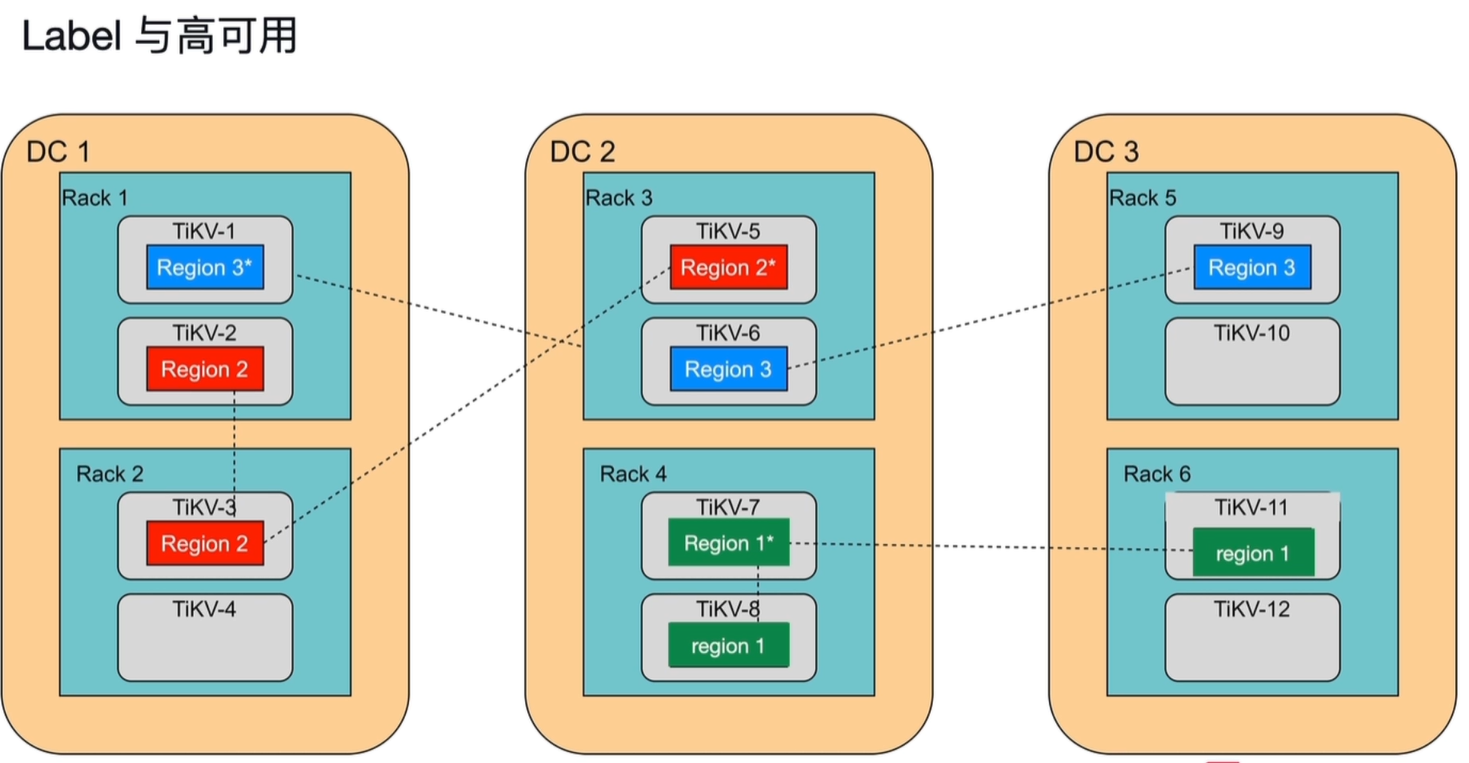
1)核心原理
TiDB 使用 Label(标签) 来定义物理拓扑层级(如数据中心、机架、机器),PD 基于这些标签实现跨层级的副本分布策略,保障集群高可用。
2)拓扑层级(结合图示)
图中展示了典型的三层拓扑结构:
- DC(数据中心):最高层级,如 DC 1、DC 2、DC 3。
- Rack(机架):每个数据中心下的机架,如 Rack 1、Rack 2。
- TiKV 节点:每个机架下的物理服务器,如 TiKV-1、TiKV-2。
3) Label 调度策略
PD 会根据配置的 Label 规则,确保每个 Region 的副本分布在不同的故障域中:
- 跨 DC 分布:同一个 Region 的副本分布在不同数据中心(如 Region 1 的副本在 DC 2 和 DC 3),防止单个数据中心故障导致数据不可用。
- 跨 Rack 分布:同一数据中心内,副本分布在不同机架(如 Region 2 的副本在 DC 1 的 Rack 1 和 Rack 2),防止单机架故障影响服务。
- Leader 分布优化:PD 会尽量将 Region Leader 分散在不同节点和机架上,平衡读写负载,避免热点。
4)高可用效果
- 故障域隔离:单个 DC、Rack 或节点故障时,只要还有多数副本存活,集群就能正常提供服务。
- 自动恢复:PD 会持续监控副本分布,一旦发现副本分布不符合 Label 策略,会自动生成调度任务,将副本迁移到合适的节点,维持高可用状态。
1.6.2 label 的配置
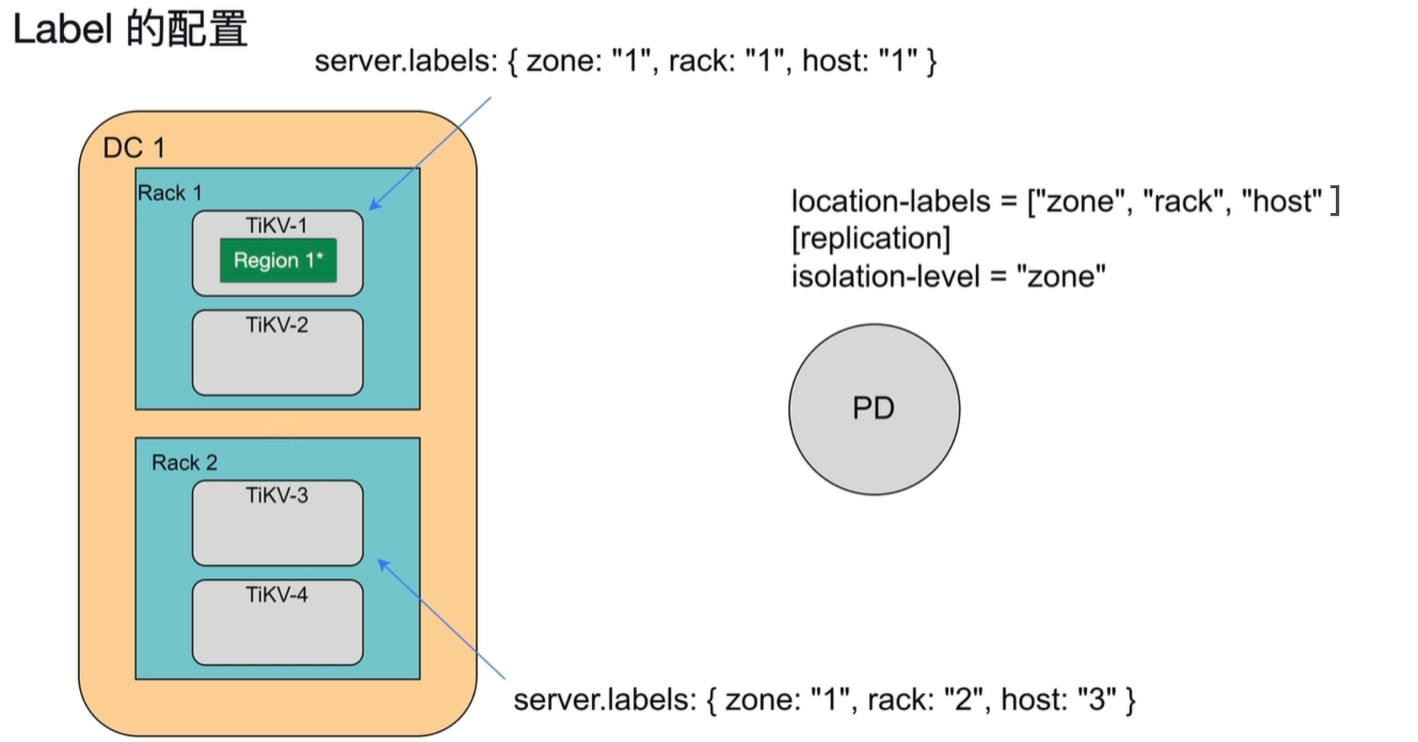
1)配置原理
TiDB 的 Label 配置分为两部分:TiKV 节点标签配置 和 PD 副本分布策略配置,两者配合实现跨故障域的高可用部署。
2)TiKV 节点 Label 配置
在 TiKV 配置文件中,通过 server.labels 参数为每个节点打上物理拓扑标签,示例如下:
# TiKV-1 (DC 1, Rack 1)
server.labels: { zone: "1", rack: "1", host: "1" }
# TiKV-3 (DC 1, Rack 2)
server.labels: { zone: "1", rack: "2", host: "3" }
zone:数据中心 / 机房层级标签。rack:机架层级标签。host:物理主机层级标签。
3)PD 副本分布策略配置
在 PD 配置文件中,通过以下参数定义副本分布规则:
location-labels = ["zone", "rack", "host"]
[replication]
isolation-level = "zone"
location-labels:指定参与副本分布策略的标签层级顺序(从高到低)。isolation-level:设置副本分布的故障域隔离级别。示例中isolation-level = "zone"表示 PD 会确保同一个 Region 的副本分布在不同的zone(数据中心)中,防止单数据中心故障导致数据不可用。