

PCTA学习笔记,依据官方文档和官方提供的视频进行整理的。
今天学习,数据库 SQL 执行流程,Lesson 05
官方文档:https://pingkai.cn/docs/tidb/stable/tidb-computing
PCTA必学课程:101-TiDB 数据库核心原理与架构:https://learn.pingkai.cn/learner/course/1290025
一、Module 01:TiDB数据库架构
1、描述 DML 语句读写流程
1.1 DML 语句读流程概要

1.1.1 流程总览
用户发送读请求,经过 TiDB Server 解析、编译、执行,最终从 TiKV 获取数据并返回。
1.1.1 分步解析
-
Protocol Layer(协议层)
- 接收用户发送的 SQL 请求,进行协议解析与权限校验。
-
Parse(解析阶段)
- 解析 SQL 语句,生成抽象语法树。
- 向 PD 请求本次读操作的 TSO(时间戳),作为事务的一致性读快照。
-
Compile(编译阶段)
- 将语法树编译为执行计划。
- 根据表结构和索引信息,向 PD 发起
Locate Region请求,查询数据所在的 TiKV 节点和 Region 位置。
-
Execute(执行阶段)
- 根据编译阶段获取的 Region 信息,向对应的 TiKV 节点发起数据读取请求。
- 读取请求被发送到 TiKV 的
UnifyRead Pool(统一读池)中,按层级(L0/L1/L2)处理,从底层rocksdb kv存储引擎中获取数据。
-
结果返回
- TiKV 将查询结果返回给 TiDB Server,再经由
Protocol Layer封装成用户可识别的格式返回给客户端。
- TiKV 将查询结果返回给 TiDB Server,再经由
1.2 DML 语句写流程概要

1.2.1 流程总览
用户发送写请求,TiDB Server 按事务流程处理,最终通过 Raft 协议将数据写入 TiKV,保证数据一致性。
1.2.2 分步解析
-
Protocol Layer(协议层)
- 接收用户写请求,进行协议解析与权限校验。
-
Parse(解析阶段)
- 解析 SQL 语句,生成抽象语法树。
- 向 PD 请求事务的 Start TSO,作为事务的一致性读快照。
-
Compile(编译阶段)
- 将语法树编译为执行计划。
- 向 PD 发起
Locate Region请求,查询待写入数据所在的 TiKV 节点和 Region 位置。
-
Execute(执行阶段)
- 执行写操作,将数据变更暂存到
memBuffer(内存缓冲区)中。 Transaction模块管理事务状态,向 PD 请求事务的Commit TSO。
- 执行写操作,将数据变更暂存到
-
TiKV 写入流程
- TiDB 将事务的预写请求发送到 TiKV。
- TiKV 的
Scheduler接收请求,交由Raftstore处理。 Raftstore通过 Raft 协议将数据同步到 Region 的所有副本,写入rocksdb raft日志。- 当多数副本同步完成后,
Apply模块将数据应用到rocksdb kv存储引擎中。
-
结果返回
- TiKV 向 TiDB 发送写入成功的确认。
- TiDB 收到确认后,提交事务并向用户返回成功响应。
2、描述 DDL 语句的执行流程
2.1 DDL 流程概要
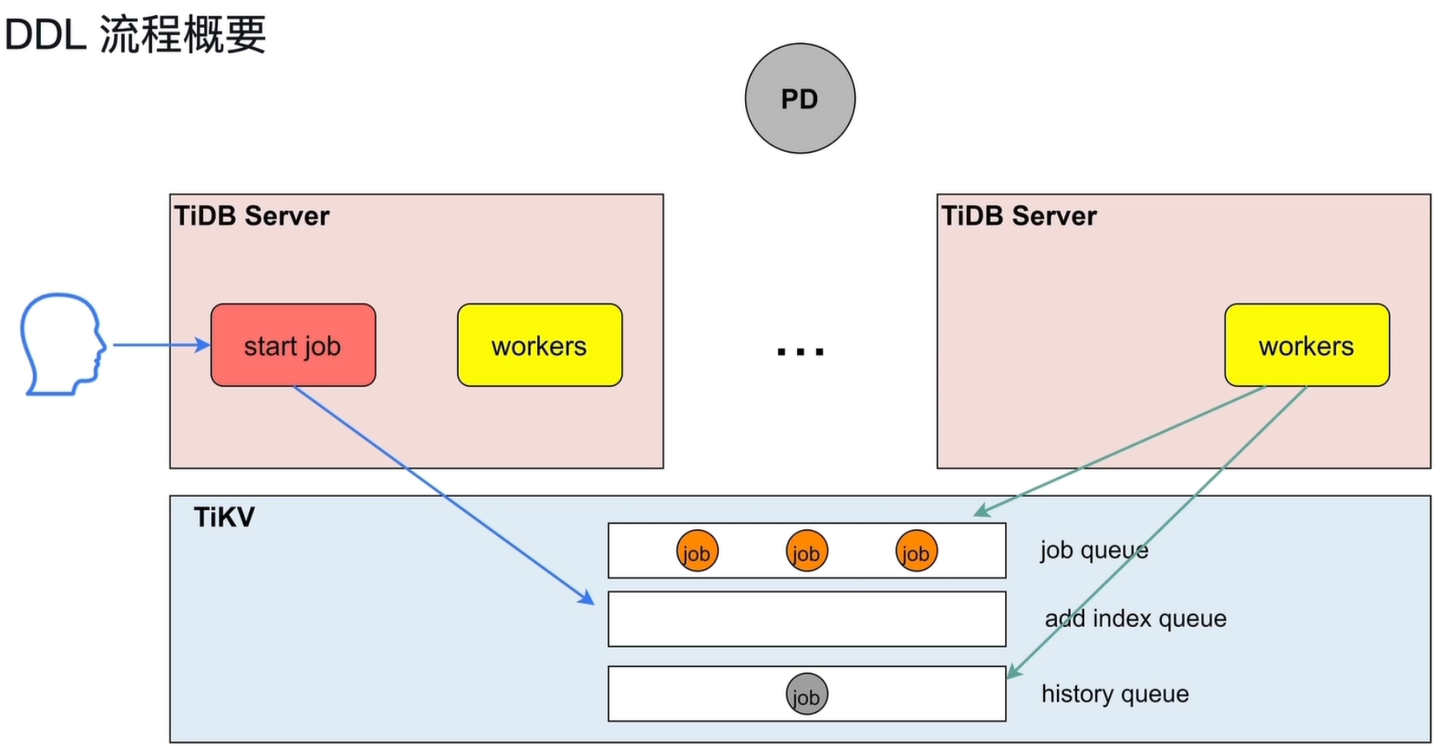
2.1.1 流程总览
DDL(数据定义语言)采用在线异步执行模式,通过分布式任务队列保证多 TiDB Server 间的协同,避免阻塞业务。
2.1.2 DDL 核心队列与 Owner 机制
- job queue:存放非加索引类的 DDL 操作(如建表、删表、修改字段)
- add index queue:专门存放加索引类的 DDL 操作
- history queue:执行完成的 DDL 操作会移入此队列,用于历史归档
2.1.3 DDL 执行规则
- 任意 TiDB Server 节点都可以接收用户的 DDL 请求
- 只有拥有 owner 角色的 TiDB Server,其内部 workers 才能真正执行队列中的 DDL 命令
- owner 采用周期性选举机制,每隔一段时间重新选举,节点轮流担任 owner,保证负载均衡与高可用
2.1.2 分步解析
-
start job(任务发起)
- 用户发送 DDL 语句(如建表、加索引),由接收到请求的 TiDB Server 作为发起节点。
- 该节点将 DDL 任务封装成
job,写入 TiKV 中的job queue(任务队列)。
-
任务调度与执行
- 集群中拥有owner角色 TiDB Server 的
workers进程会监听job queue(非索引类)、add index queue(索引类),抢占并执行任务。
- 集群中拥有owner角色 TiDB Server 的
-
任务完成与归档
- DDL 任务执行完成后,状态变更会被写入
history queue,作为任务的最终归档记录。 - 即使发起任务的 TiDB Server 下线,其他节点的
workers也能从队列中接管任务,保证 DDL 最终完成。
- DDL 任务执行完成后,状态变更会被写入
-
高可用保障
- PD 不直接参与 DDL 执行流程,但提供集群元数据与节点状态管理,间接保障 DDL 任务的调度与节点故障恢复。
3、SQL 的 Parse 与 Compile
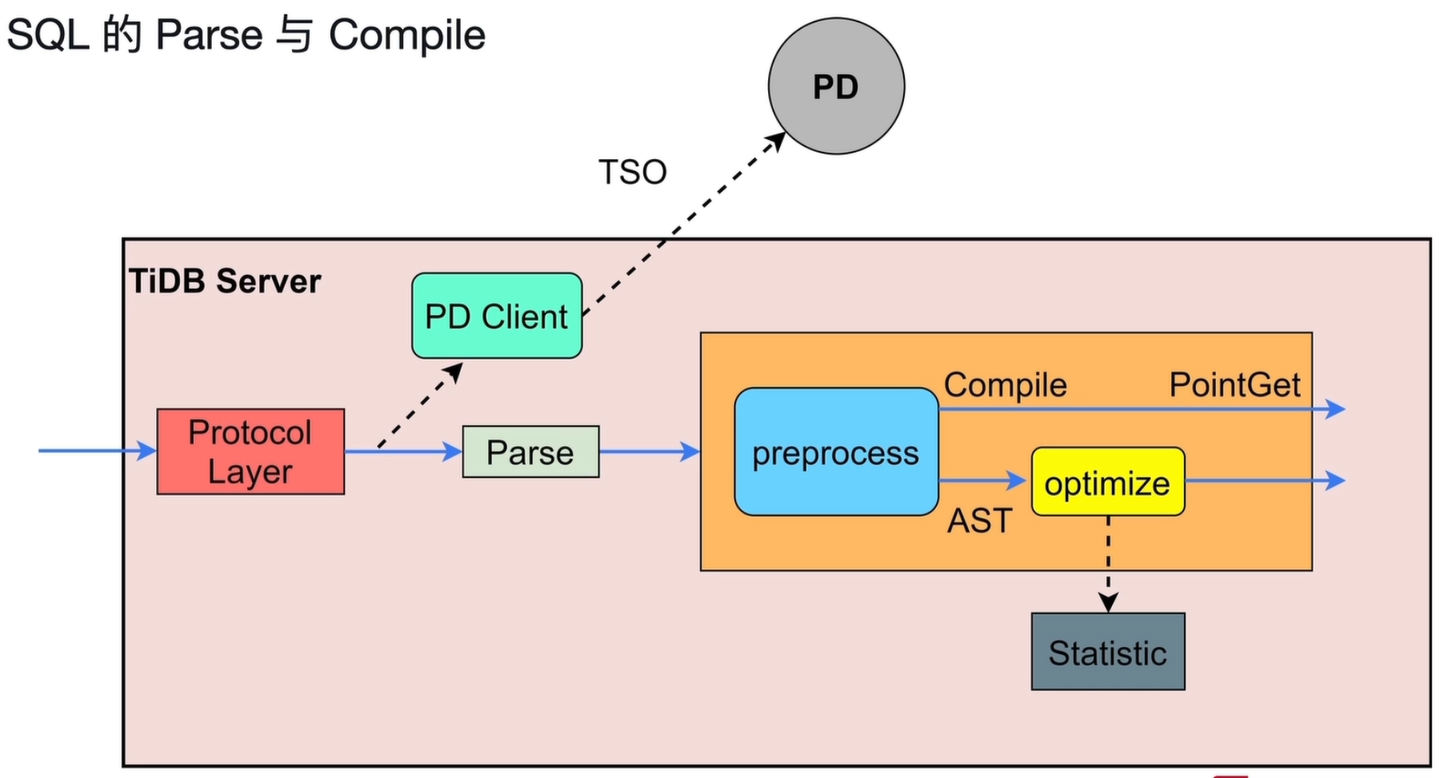
3.1 流程总览
SQL 语句进入 TiDB Server 后,会经过解析(Parse)、预处理(Preprocess)、编译(Compile)与优化(Optimize),最终生成可执行的执行计划。
3.2 分步解析
-
Protocol Layer(协议层)
- 接收客户端的 SQL 请求,进行协议解析、权限校验与连接管理。
- 监听并接收客户端发送的 SQL 请求。
-
Parse(解析阶段)
- 将 SQL 文本解析为抽象语法树(AST),完成词法与语法分析。
- 同时,
PD Client向 PD 申请本次操作所需的 TSO(时间戳),用于事务一致性控制。
-
Preprocess(预处理阶段)
- 对语法树进行预处理(合法性校验),包括名称解析、类型检查、权限校验等。
- 判断 SQL 是否为点查(主键查询、唯一索引查询等简单查询场景)
- 复杂查询预处理后,将 AST 传递给后续的编译与优化流程。
-
Compile(编译阶段)
- 针对点查(如
PointGet主键查询),直接生成优化后的快速执行路径,无需复杂优化,提升性能。
- 针对点查(如
-
Optimize(优化阶段)
- 对非点查语句进行逻辑优化(如常量折叠、谓词下推)和物理优化(如索引选择、连接顺序调整)
- 基于
Statistic(统计信息)对执行计划进行优化。 - 生成最终的物理执行计划,供后续Executor 执行阶段使用。
4、读取的执行
4.1 流程总览
执行阶段的核心是:根据优化后的执行计划,定位数据所在的 TiKV 节点,通过缓存或直接查询获取数据,并最终返回结果。

4.2 分步解析
-
Executor 执行器
- 接收编译优化后的执行计划。
- 读取
information schema(信息 schema)中的表元数据,确定查询涉及的表、索引结构。 - 向
TiKV Client发起数据读取请求。
-
TiKV Client 与 Region 定位
- 首先查询本地的
region Cache,获取数据所在的 Region 位置信息。 - 若缓存未命中或失效,通过
PD Client向 PD 发起Locate Region请求,查询最新的 Region 分布。 - 更新
region Cache,为后续请求提供缓存支持,减少对 PD 的频繁访问。
- 首先查询本地的
-
请求分发与执行
-
根据查询类型,选择对应的执行方式:
KV:直接点查(主键/唯一索引查询),直接向 TiKV 发送 Get 请求。DistSQL:分布式 SQL 查询(如聚合、Join、范围扫描),向 TiKV 发送分布式执行请求。
-
-
TiKV 数据读取
- TiKV 接收到请求后,交由
UnifyRead Pool(统一读池)处理。 - 请求按层级(L0/L1/L2)从
rocksdb kv存储引擎中读取数据,不同层级代表不同的缓存与存储介质,优先从上层缓存读取以提升性能。
- TiKV 接收到请求后,交由
-
结果返回
- TiKV 将查询结果返回给 TiDB Server,Executor 对数据进行处理(如聚合、排序),最终封装成用户可识别的格式返回。
4.3 Region 变更与 Backoff 机制
- 当 Region 发生变化(如 Leader 迁移、分裂或合并)时,
region Cache中存储的信息会失效。 - 此时会触发 Backoff 机制:TiDB 收到失效响应后,暂停当前请求,重新向 PD 拉取最新的 Region 信息,更新本地缓存,再使用新的路由信息重试请求。
- 整个过程对业务透明,确保请求最终能路由到正确的 TiKV 节点。
4.4 两种读取模式的执行流程
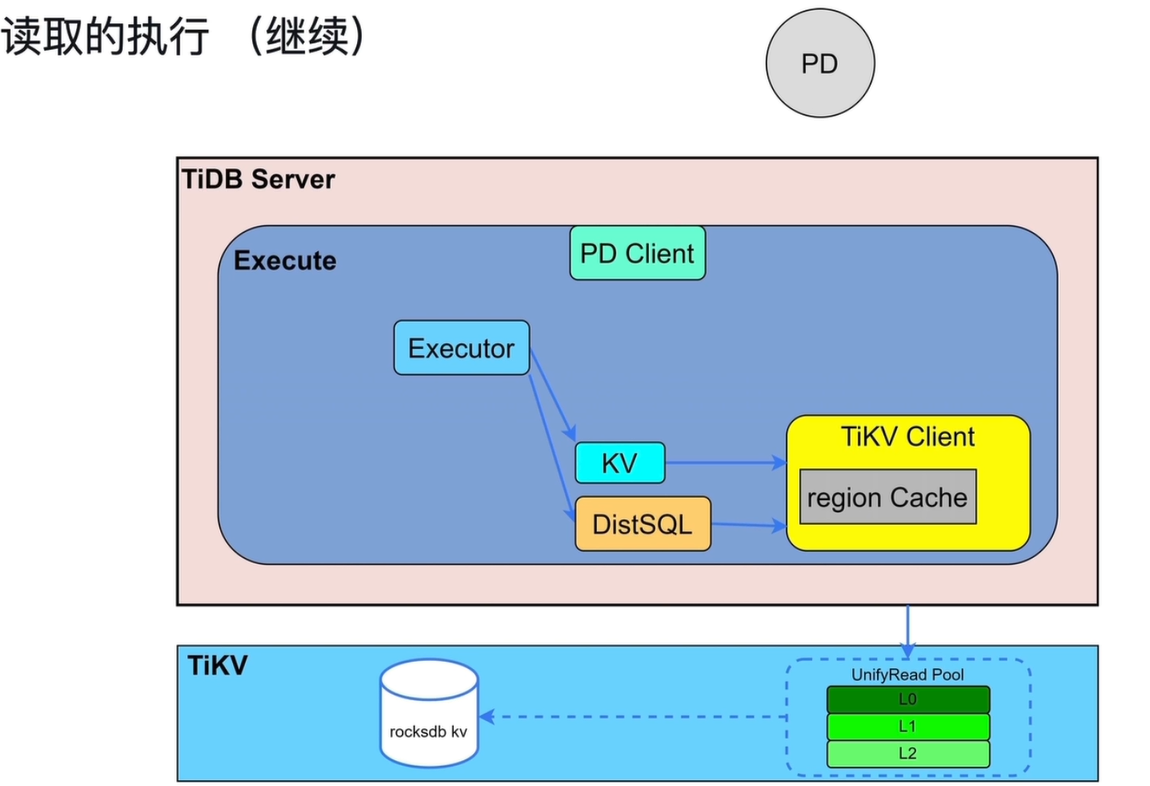
Executor 分发请求 Executor 根据执行计划,将读请求分发给两种执行引擎:
- KV 模式:处理简单的点查(主键/唯一索引查询)。
- DistSQL 模式:处理复杂查询(如范围扫描、聚合、Join 等)。
-
TiKV Client 处理请求 两种模式的请求都会发送到
TiKV Client:- 它会先查询
region Cache,获取数据所在的 Region 位置信息。 - 若缓存失效或未命中,则会通过
PD Client向 PD 拉取最新信息,并更新缓存。
- 它会先查询
-
TiKV 数据读取 请求被发送到 TiKV 后,由
UnifyRead Pool(统一读池)处理:- 读池分为 L0/L1/L2 三层,优先从上层缓存读取数据(性能更高)。
- 若缓存未命中,则从底层的
rocksdb kv存储引擎中读取数据。
-
结果返回与处理
- TiKV 将读取结果返回给 TiDB Server。
- Executor 对结果进行后续处理(如聚合、排序),最终封装成用户可识别的格式返回给客户端。
4.5 结果返回流程
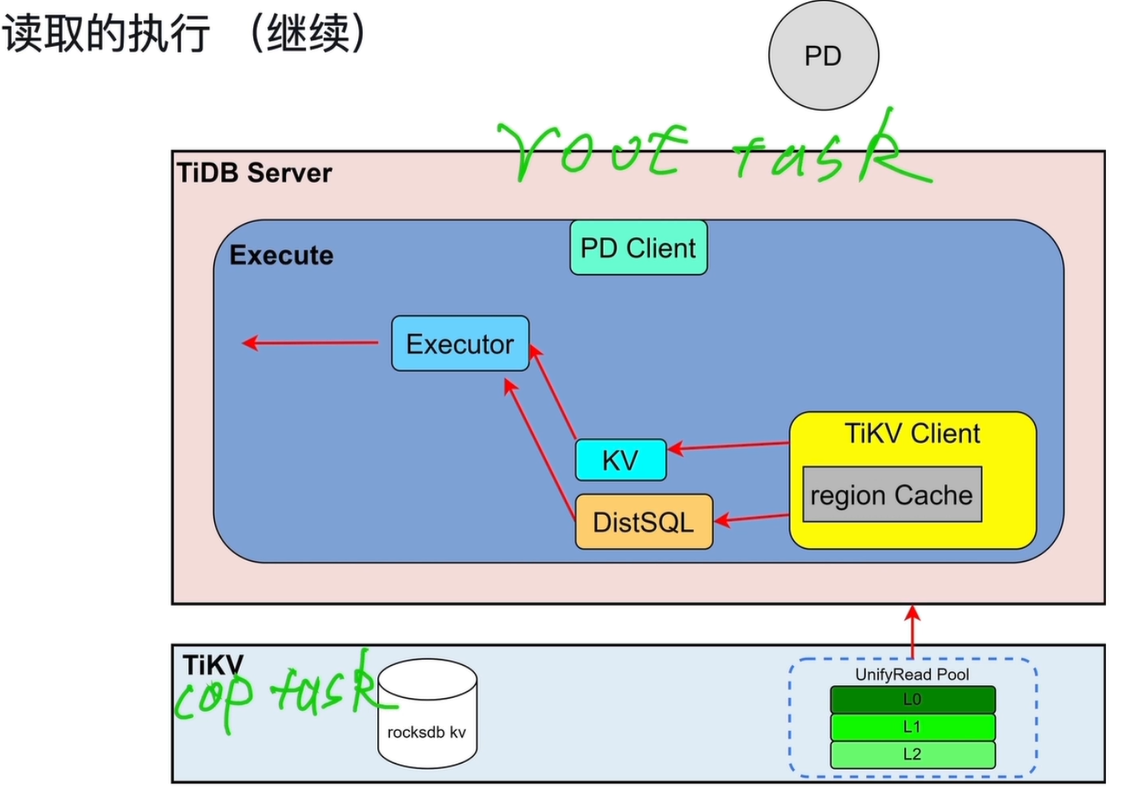
TiKV 读取完成 TiKV 从 UnifyRead Pool 中处理完请求后,从 rocksdb kv 存储引擎中获取数据。 读取结果会返回给 TiDB Server 中的 TiKV Client。
- 数据分发与处理
-
TiKV Client将读取结果分别返回给KV或DistSQL模块:KV:点查结果直接返回给Executor。DistSQL:复杂查询结果(如聚合、Join 中间结果)返回给Executor,由其进行后续计算与合并。
-
Executor 处理与返回
Executor收到数据后,根据执行计划完成后续处理(如排序、聚合、过滤),最终生成用户需要的结果集,并通过Protocol Layer返回给客户端。 -
Cop Task(算子下推任务)
- 定义:将 SQL 计算算子下推到 TiKV 侧执行的分布式任务
- 执行位置:在各个 TiKV 节点本地完成计算
- 典型计算:过滤(where)、聚合(sum/count/max/min)、排序、limit 等
- 优势:只返回计算后的精简结果,大幅减少网络传输,提升性能
- 一句话理解:在 TiKV 上先算完,再把结果给 TiDB
-
Root Task(汇总计算任务)
-
定义:无法下推、必须在 TiDB Server 内存中完成的计算任务
-
执行位置:TiDB Server
-
典型场景:
- 数据分散在多个 TiKV 节点
- 需要合并多个 Cop Task 结果
- 表连接(Join)、复杂聚合、跨节点排序等
-
一句话理解:收集所有 TiKV 返回的结果,在 TiDB 做最终汇总/计算
-
5. 写入的执行流程
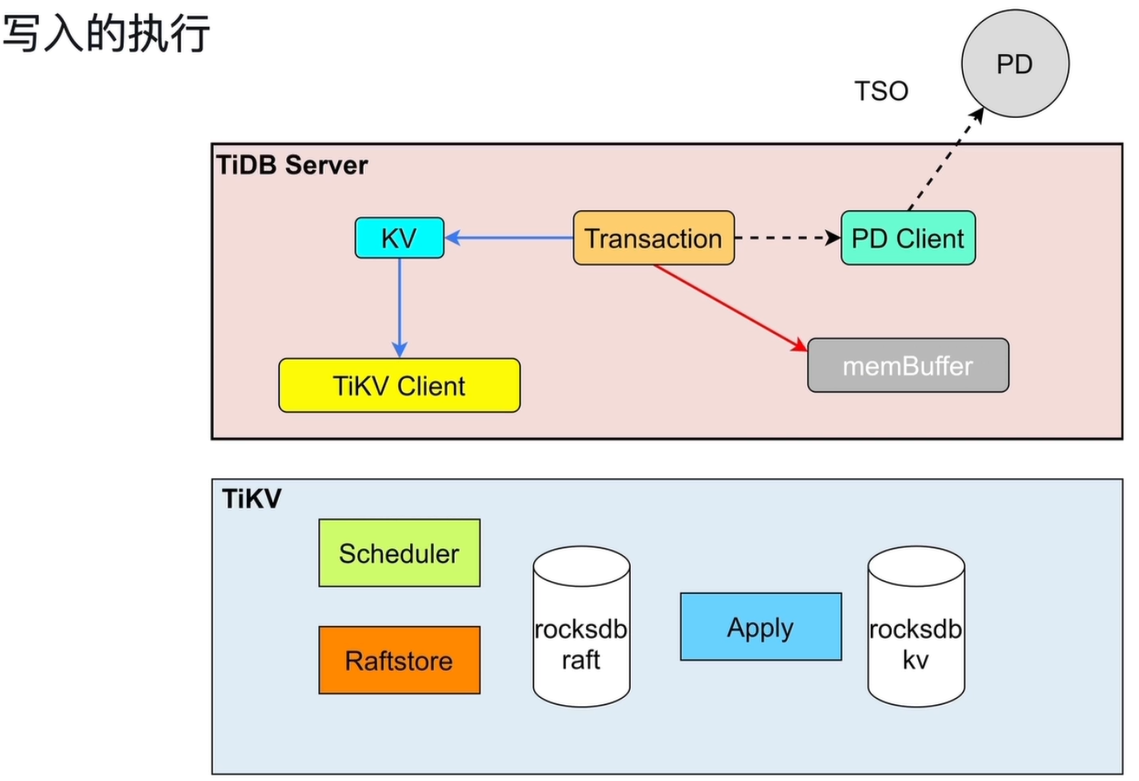
5.1 TiDB Server 端处理流程
-
Transaction(事务模块)
- 向 PD Client 申请事务的 TSO(时间戳),用于事务一致性控制。
- 将事务的写操作先暂存到
memBuffer(内存缓冲区)中,未直接写入 TiKV,实现事务的原子性与可回滚性。 - 事务准备阶段,将数据变更通过
KV模块发送给TiKV Client。
-
TiKV Client
- 根据 Region 缓存定位数据所在的 TiKV 节点,向对应节点发送预写请求。
-
两阶段提交:先预写(Prepare)再提交(Commit),保证分布式事务的原子性。
-
内存缓冲:事务变更先存于
memBuffer,失败时直接丢弃,无需回滚 TiKV 数据。
5.4 TiKV 写入的完整流程

5.4.1 TiKV端各组件职责
-
Scheduler(调度器)
-
核心职责:
- 协调事务的并发写入,解决数据冲突。
- 管理请求的执行顺序,将修改操作向下传递给
Raftstore。
-
冲突处理机制:
- 当多个请求修改同一个 Key 时,使用 Latch(锁) 机制控制并发。
- 只有成功获取 Latch 的请求才能继续向下写入,未获取到的请求会等待,避免脏写和数据不一致。
-
-
Raftstore
-
核心职责:
- 将收到的写请求转换为 Raft Log(Raft 日志)。
- 持久化日志到本地的
rocksdb raft(Raft 日志存储)确保写入不丢失。 - 向 Region 的其他副本节点发送日志,通过 Raft 协议完成数据同步。
-
关键作用:
- 保证数据写入的一致性与高可用,只有当多数副本确认日志写入后,预写阶段才算成功。
-
-
Apply(应用阶段)
-
将预写日志应用到
rocksdb kv(实际数据存储引擎),完成数据写入。 -
写入完成后,向 TiDB 返回事务提交成功的确认。
-
核心职责:
- 将已同步成功的 Raft Log 异步应用到
rocksdb kv(实际数据存储引擎)存储引擎中。 - 完成数据的实际写入,使变更对后续读请求可见。
- 将已同步成功的 Raft Log 异步应用到
-
优势:
- 日志同步和数据应用分离,既保证了写入性能,又避免了同步写入对响应时间的影响。
-
5.4.2 TiKV端处理流程
-
请求接收 TiKV 接收到 TiDB 的预写请求,交由
Scheduler调度器处理。 -
Raft 日志同步
Scheduler将请求转发给Raftstore。Raftstore通过 Raft 协议,将预写日志(raft log)同步到 Region 的所有副本节点。- 日志写入
rocksdb raft存储,保证数据持久化。
-
多数派确认 当 Region 内多数副本节点完成日志写入后,预写阶段成功,TiKV 向 TiDB 返回事务提交确认。
-
数据应用(Apply)
Apply模块异步将rocksdb raft中的日志应用到rocksdb kv存储引擎中,完成实际数据写入。- 应用完成后,数据对后续读请求可见。
-
关键特性说明
- 日志先行:数据先以日志形式写入
rocksdb raft,再异步应用到rocksdb kv,保证写入性能与一致性。 - 高可用保障:Raft 协议确保数据写入多数副本,单个节点故障不会导致数据丢失。
- 读写分离:预写阶段与数据应用阶段分离,提升写入吞吐量的同时,不影响读请求的响应速度。
- 日志先行:数据先以日志形式写入
6. DDL 的执行
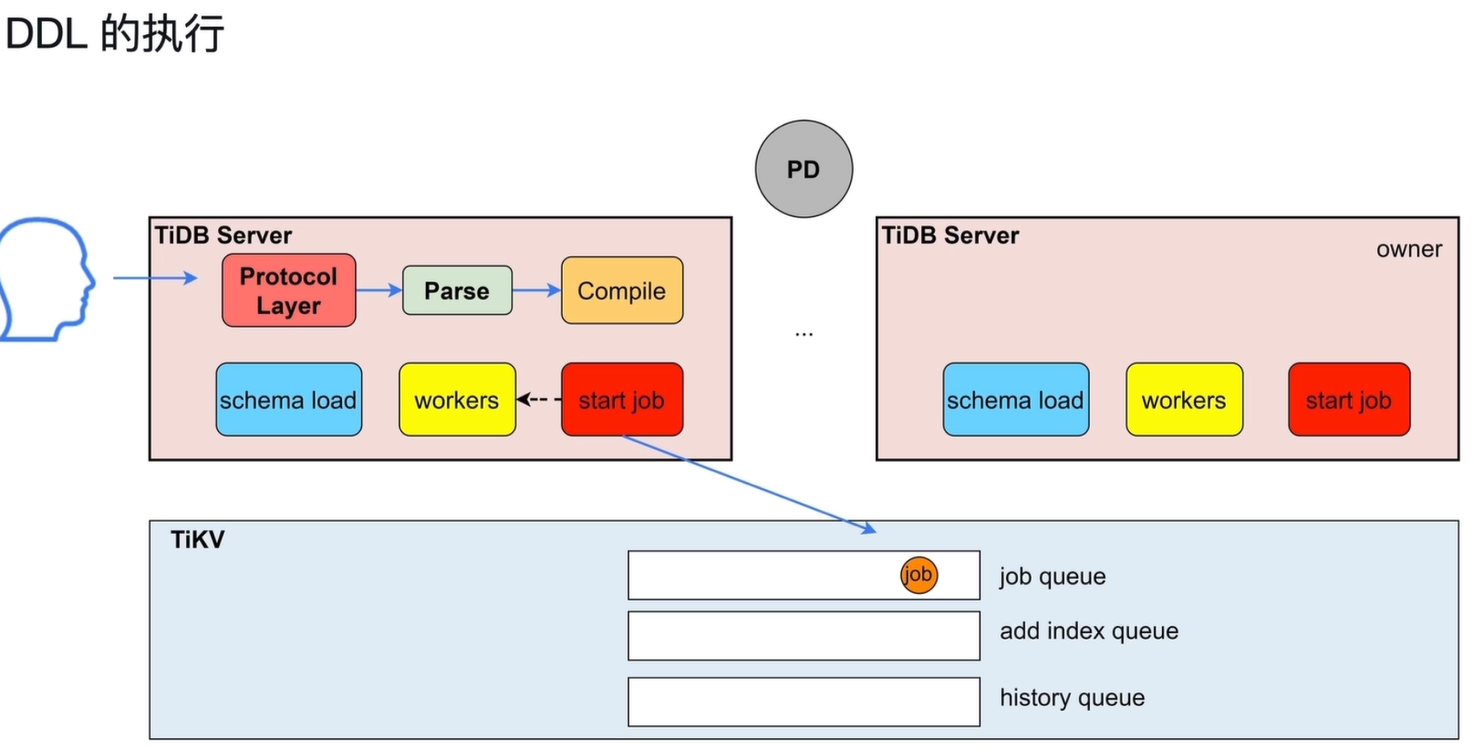
6.1 用户请求处理流程
-
请求接收:用户发送 DDL 语句, TiDB Server 的
Protocol Layer接收。 -
解析与编译:请求经过
Parse(词法 / 语法分析)和Compile(生成任务)阶段,生成标准化的 DDL 任务。 -
任务持久化:任务通过 start job 写入 TiKV 中对应的队列:
- 普通 DDL 任务:写入
job queue - 加索引类任务:写入
add index queue
- 普通 DDL 任务:写入
6.2 Owner 节点执行机制
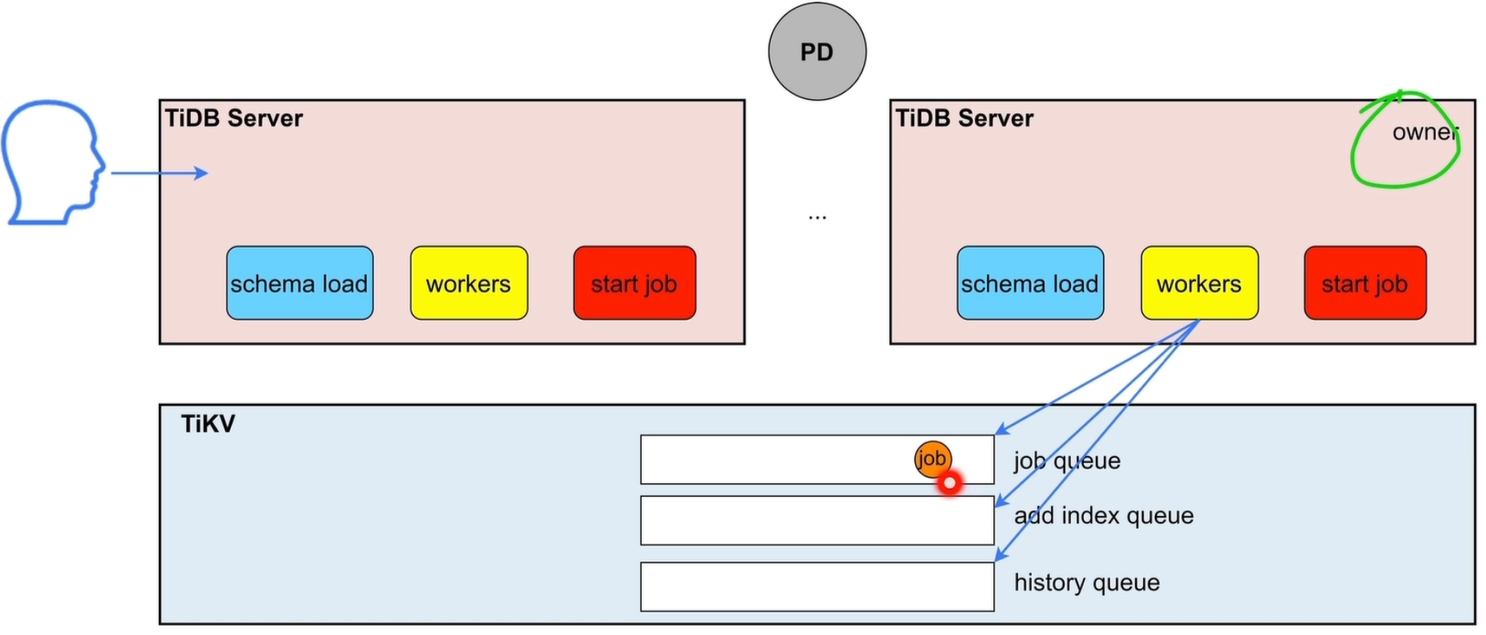
角色分工:集群中只有被选举为 owner 的 TiDB Server,其 workers 进程有权限从队列中取出并执行 DDL 任务。
- 元数据同步:
schema load模块会定期加载最新的元数据变更,确保所有 TiDB 节点感知表结构变化。
6.3 任务完成与归档
- 执行完成的 DDL 任务会被移入
history queue中归档,用于记录和追溯。 - 该设计确保了 DDL 任务的高可用、可重试性,即使发起请求的节点下线,Owner 节点仍能从队列中接管并完成任务。