

下载并安装 TPC-H
下载并编译安装 TPC-H。编译成功后,应该可以看到 dbgen 和 qgen 两个可执行文件。
# 下载 tpch 安装包,或直接使用附件下载好的 tpch-dbgen-master.zip 并解压
git clone https://github.com/electrum/tpch-dbgen.git
unzip tpch-dbgen-master.zip
cd tpch-dbgen-master
make
ls -la dbgen qgen
# 应该看到 dbgen 和 qgen 可执行文件
./dbgen -h
准备数据
创建表结构
首先使用以下命令创建 tpch 库及 tpch 用户,后续使用 tpch 用户来创建表结构
create database tpch;
create user tpch identified by 'tpch';
grant all on tpch.* to tpch;
创建表结构有两种方式,使用 tiup bench prepare 或手动执行建表语句
方法一:tiup bench tpch prepare 创建表结构
设置 --sf=0,表示只创建表结构不生成数据
tiup bench tpch prepare --sf=0 --host=192.168.2.24 --port=4000 --user=tpch --password=tpch --db=tpch
Starting component bench: /home/tidb/.tiup/components/bench/v1.12.0/tiup-bench tpch prepare --sf=0 --host=192.168.2.24 --port=4000 --user=tpch --password****** --db=tpch
creating nation
creating region
creating part
creating supplier
creating partsupp
creating customer
creating orders
creating lineitem
generating nation table
generate nation table done
generating region table
generate region table done
generating customers table
generate customers table done
generating suppliers table
generate suppliers table done
generating part/partsupplier tables
generate part/partsupplier tables done
generating orders/lineitem tables
generate orders/lineitem tables done
Finished
方法二:执行 tpch 下 dss.ddl 脚本创建表结构
cd tpch-dbgen-master
mysql> use tpch
mysql> source dss.ddl
生成数据文件
数据准备有几种方式:
| 方法 | 适用场景 | 备注 |
|---|---|---|
tiup bench tpch prepare 直接生成表并写入数据 |
适用于小数据量场景,如 10G |
使用方便,可直接创建表结构 |
tiup bench tpch prepare --output-dir /data1/backups/ --output-type=csv 生成 csv 文件 |
适用于中等数据量场景,如 100G |
可以直接生成 csv 文件 |
tpch dbgen 生成 tbl 数据文件 |
适用于大数据量场景,如 1T |
大数据量生成数据最快 |
方法一:tiup bench tpch prepare 直接创建表及写入数据——适用于小数据量场景
有关 tiup bench 使用方法,可参考 https://docs.pingcap.com/zh/tidb/stable/tiup-bench/
tiup bench tpch prepare --sf=1000 --host=192.168.2.24 --port=4000 --user=tpch --password=tpch --db=tpch
方法二:tiup bench tpch prepare 生成文件,使用 lightning local 模式导入 tidb ——适用于中等数据量场景
tiup bench tpch prepare --sf=1000 --host=192.168.2.24 --port=4000 --user=tpch --password=tpch --db=tpch --output-dir /data1/backups/ --output-type=csv
方法三:tpch dbgen 生成文件,使用 lightning local 模式导入 tidb ——适用于大数据量场景
注:默认 dbgen 生成文件在当前目录下,生成大数据量文件时建议将 dbgen 拷贝到大容量磁盘下执行
# 简单生成 1TB 数据
cd tpch-dbgen-master
# -s 1 表示生成 1G 数据,-s 1000 表示生成 1T 数据
./dbgen -s 1000 -f
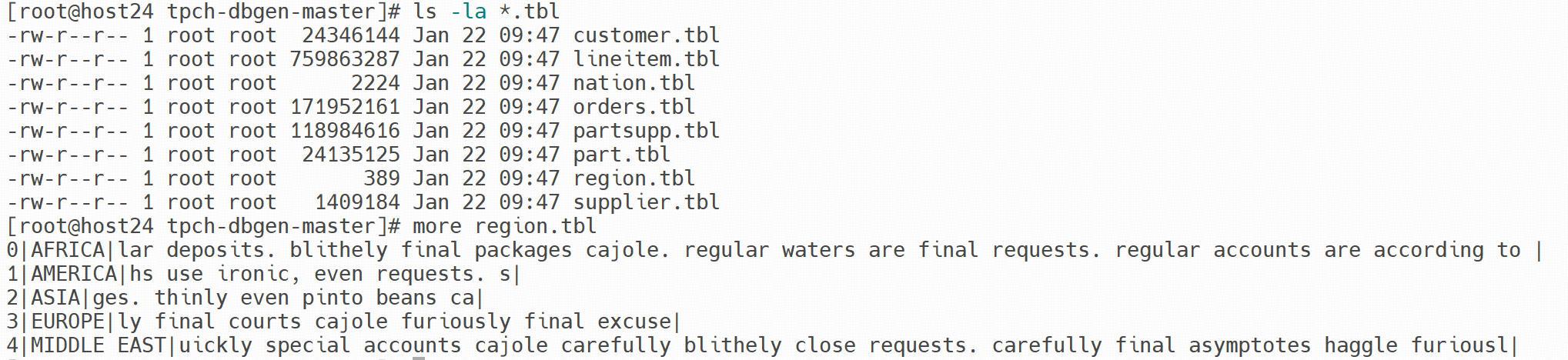
以上命令将生成 8 个 .tbl 文件,文件的前缀以表名命名,字体之间以 | 作为默认分隔符
写入数据到 TiDB
如果使用上述方法 1 直接通过 tiup bench 将数据写入表中,此步骤可以直接忽略。采用方法 2 或方法 3 生成文件的方式,需要使用 tidb lightning local 模式导入文件到 TiDB。
由于 tidb lightning 对于导入的文件名需满足 ${db_name}.${table_name}.${csv|sql|parquet} 格式,对于上述方法 3 - 使用 dbgen 生成的文件,需要对文件名先进行 rename 处理,处理后的文件名如下图所示(方法 2 - 使用 tiup bench prepare 产生的 csv 文件不需要此 rename 动作)。
for file in *.tbl; do
mv "$file" "tpch.${file%.tbl}.csv"
done

编辑准备以下 lightning.yaml 配置文件,用于执行 lightning 导入
[lightning]
level = "info"
file = "tidb-lightning.log"
check-requirements=true
region-concurrency = 128
table-concurrency = 32
index-concurrency = 16
io-concurrency = 32
[tikv-importer]
backend = "local"
sorted-kv-dir = "/data5/ssd/sorted-kv-dir"
[mydumper]
data-source-dir = "/data5/tpch"
strict-format = true
max-region-size = "80MiB"
[mydumper.csv]
header = false
delimiter = ''
terminator = "\n"
separator = "|"
null = '\N'
backslash-escape = false
[tidb]
host = "xx.xx.xx.xx"
port = 6000
user = "xxx"
password = "xxx"
status-port = 10080
pd-addr= "xx.xx.xx.xx:2379"
[post-restore]
checksum = true
analyze = false
使用 Lightning 导入数据,为避免直接在命令行使用 nohup 启动程序时因 SIGHUP 信号导致的程序退出,将 nohup 命令放入脚本中。
!/bin/bash
nohup tiup tidb-lightning -config lightning.toml > nohup.out &
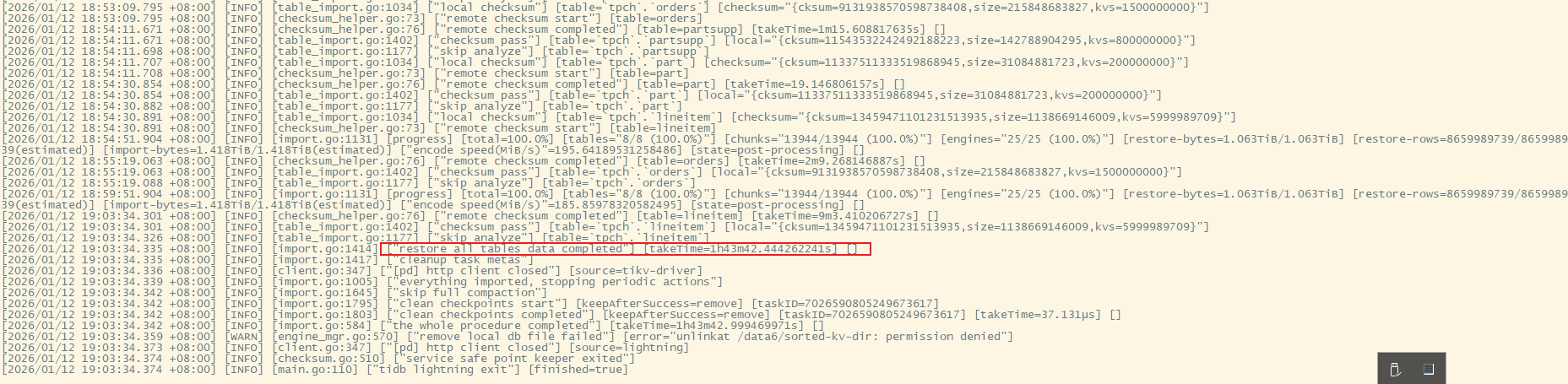
本次测试导入 1TB 数据到 TiDB 耗时 1小时43分钟
创建 TiFlash 副本
数据导入完成后,先针对 TPCH 生成的表创建 TiFlash 副本,可以选择直接给 tpch 整个 database 添加列存副本,也可以单独为每张表添加列存副本。添加列存副本的进度通过 information_schema.tiflash_replica 查看,PROGRESS=1 表示副本创建成功。
注:如果添加 tiflash 副本较慢,可以通过修改相应参数加快 TiFlash 副本同步速度,具体参考 构建 TiFlash 副本
SET CONFIG tikv server.snap-io-max-bytes-per-sec = '300MiB';
SET CONFIG tiflash raftstore-proxy.server.snap-io-max-bytes-per-sec = '300MiB';
tiup ctl:v<CLUSTER_VERSION> pd -u http://<PD_ADDRESS>:2379 store limit all engine tiflash 60 add-peer
ALTER DATABASE tpch SET TIFLASH REPLICA 2;
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = 'tpch';


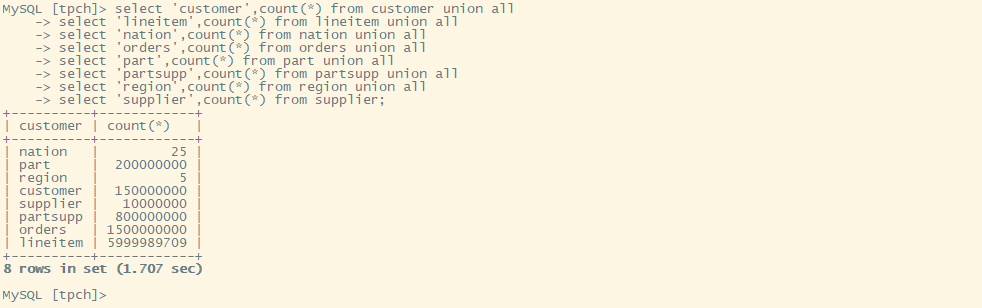
表行数统计
在成功添加 TiFlash 副本的情况下,count 记录数可以很快执行,以下是 8 张表的行数统计情况
收集统计信息
通过 analyze table 命令为每张表收集统计信息
注意:
- 在 analyze 之前设置 tidb_analyze_column_options='ALL'; 否则 Query9 会因为执行计划问题而导致 TiFlash OOM
- 在 analyze 之前设置 tidb_analyze_distsql_scan_concurrency=128 以加速 analyze 时间,默认值 4 会导致 analyze 时间较长
select @@tidb_analyze_column_options;
set global tidb_analyze_column_options='ALL'; --需要打开,否则可能导致执行计划不准确
set global tidb_analyze_distsql_scan_concurrency=128; --临时调大,否则大表更新统计信息很慢
analyze nation;
analyze region;
analyze part;
analyze supplier;
analyze partsupp;
analyze customer;
analyze orders;
analyze lineitem;
参数优化设置
在执行 TPC-H Query 语句的环境,设置以下参数。
set global tidb_default_string_match_selectivity=0.5;
set global tidb_opt_join_reorder_threshold=63;
执行 TPC-H 测试
注意:
为了保证所有语句执行都能全部走 TiFlash,测试前需要设置 tidb_isolation_read_engines = 'tidb,tiflash'
执行 TPC-H 22 条语句有 2 种方式,本次测试使用方式 2,进行了多轮次测试
- tiup bench tpch run 一键运行所有语句
set @@session.tidb_isolation_read_engines='tidb,tiflash';
tiup bench tpch run --count=22 --sf=1 --host=192.168.2.24 --port=24000 --user=root --password=root123 --db=tpch
- 根据 sql 语句一条一条执行
注:SQL 语句也可以通过 tpch 目录下的 qgen 生成,以上命令将在当前目录下生成 query1.sql~query22.sql 文件,但这些文件中最后一行会默认带 where rownum <= -1; 需要删除此行或修改为 limit 语句。可以直接使附录中的 SQL 语句。
cd tpch-dbgen-master
cp -r queries/* .
for i in {1..22}; do sudo ./qgen -s 1000 $i > query$i.sql; done
关于 TPCH
TPC-H 是由 事务处理性能委员会(TPC) 制定的一个面向决策支持系统的基准测试,主要用于衡量数据库系统在复杂分析查询(OLAP, Online Analytical Processing)和高并发场景下的性能。它模拟了数据仓库和商业智能场景中的典型查询负载。
-
数据模型
-
采用 星型模型(Star Schema),包含 8 张表:
- 1 张事实表:
lineitem(订单明细) - 7 张维度表:
orders,customer,part,supplier,partsupp,nation,region
- 1 张事实表:
-
数据量可扩展,通过 比例因子(Scale Factor, SF) 定义(如 SF=1 表示数据集约 1GB)。
-
-
查询负载
- 包含 22 个复杂分析查询(Q1-Q22),涵盖多表连接、聚合、子查询、排序等操作。
- 查询设计模拟实际业务场景(如销售分析、库存统计、客户行为分析等)。
-
测试指标
- QphH (Query per Hour H): 每小时完成的查询数,综合衡量吞吐量和响应时间。
- Price/QphH: 性价比(硬件+软件成本 / QphH)。