初来乍到
(Ti D Ber 4c Cgc Gp L)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】7.0.0
源tidb 使用tiup br 全量备份,每个节点约1.1T 数据。然后在目标(新)tidb 恢复数据,恢复时候使用cdc 实现目标tidb 从源tidb同步数据。当前恢复后的tidb与源tidb之间存在约40个小时的落后。启动cdc changefeed 后,查看各项state 是normal 但是checkpoint_tso 与heckpoint_time 不变,未发现表数据增长
【遇到的问题:问题现象及影响】
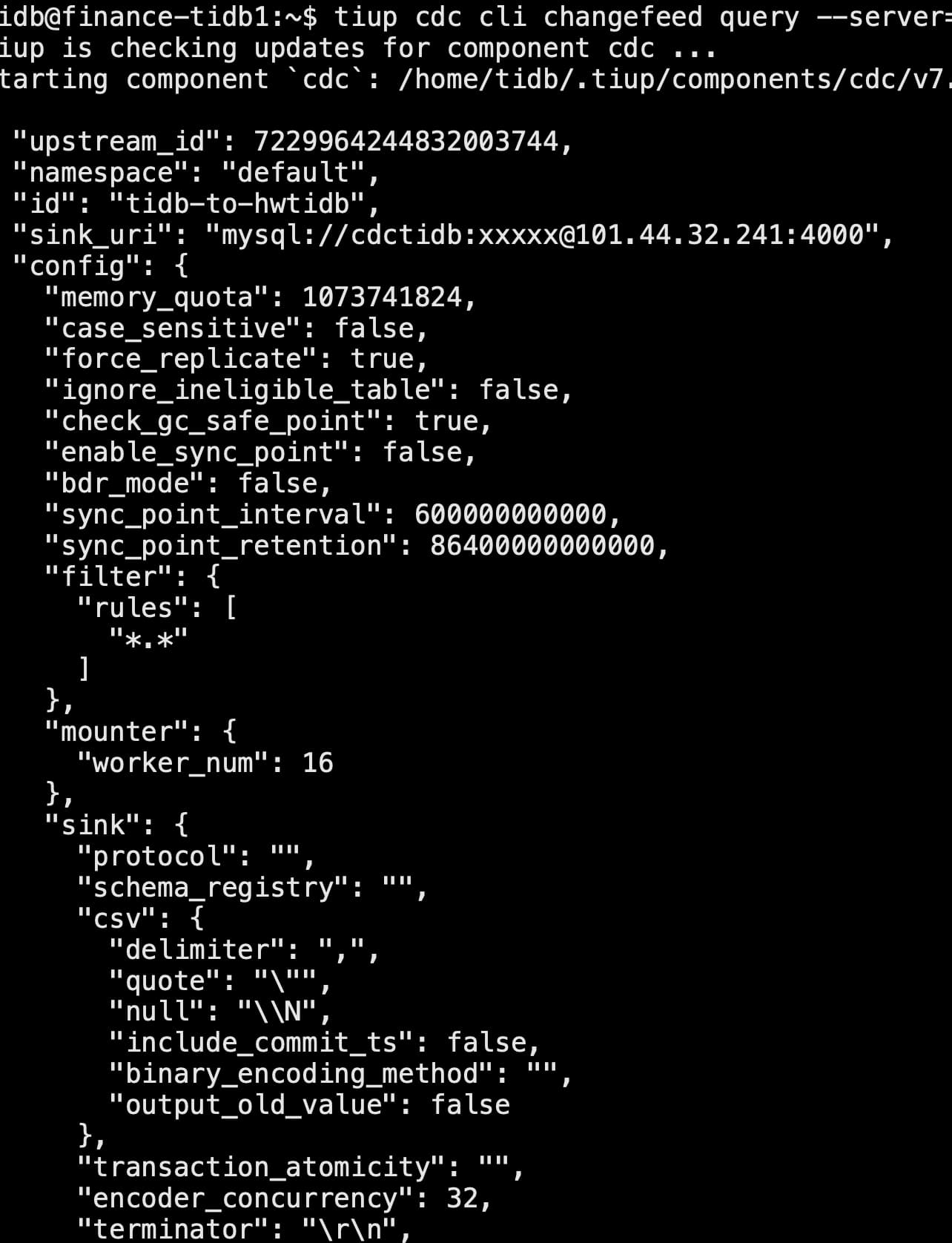
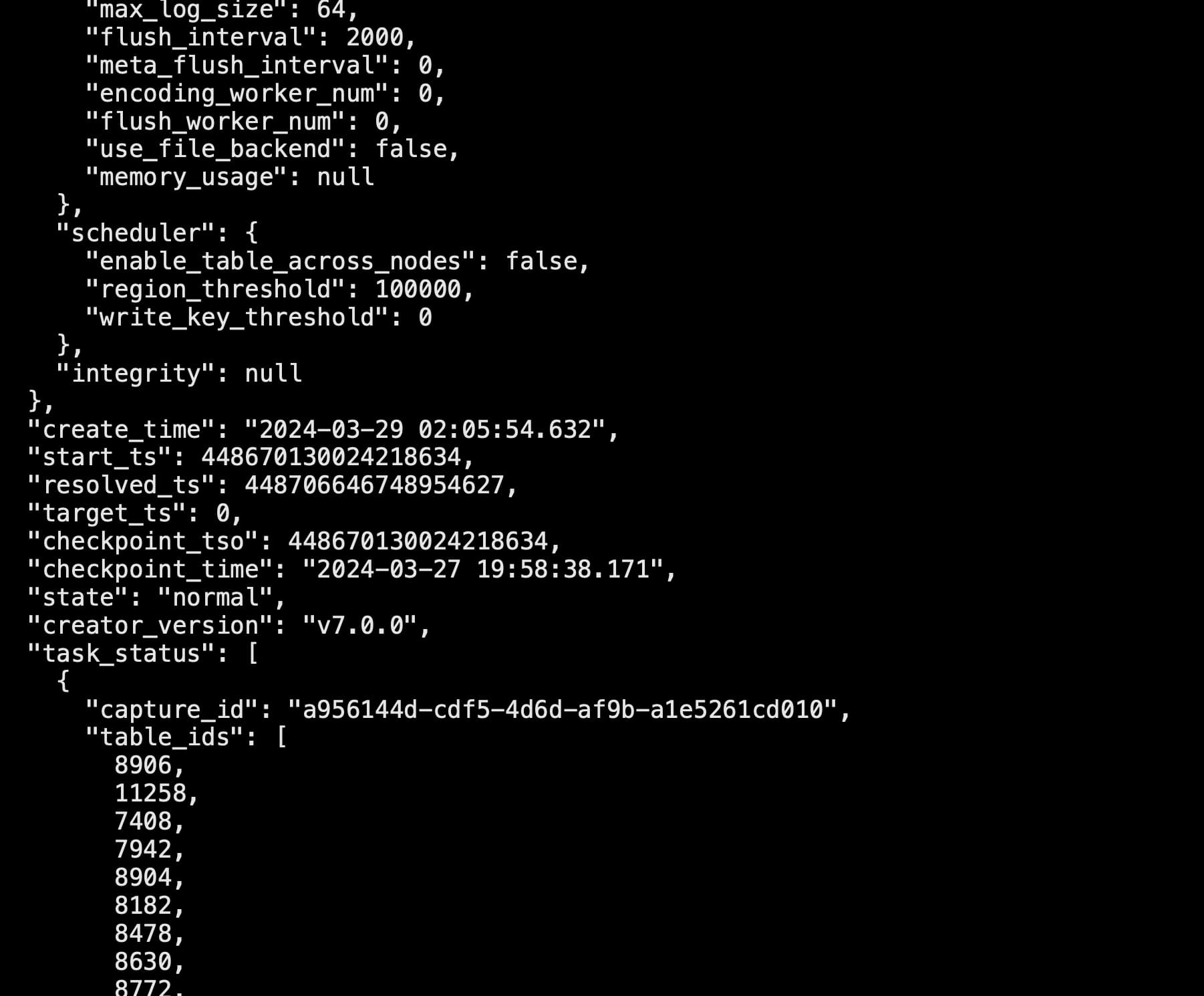
tiup cdc cli changefeed list
query 信息
哪位大神帮忙看一下 不胜感激
初来乍到
(Ti D Ber 4c Cgc Gp L)
3
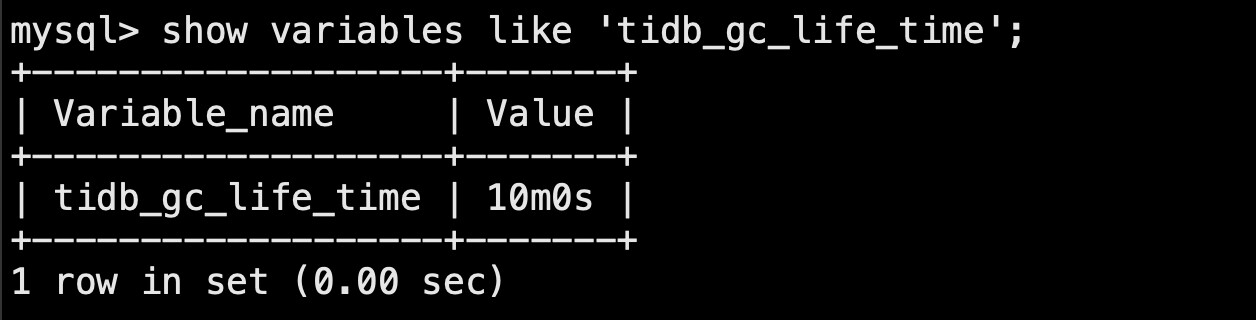
不懂您说的gc 是哪个设置
备份完成时 提示的 [BackupTS=448670130024218634] [RestoreTS=448693405611458561]
我就使用的BackupTS 作为cdc的BackupTS
Denis
4
tidb_gc_life_time
tidb_gc_life_time
1 个赞
vcdog
(Vcdog)
5
如果数据量超过1T,建议对库中的比较大的表,进行cdc任务的单独拆分同步,其他的小表可以合并到一个任务同步。这样,便于观察发现,到底是哪个业务表同步数据时,被卡住。
另外,在主库集群备份前,需要将gc的时间调整尽量大一些,比如:48小时或72小时。
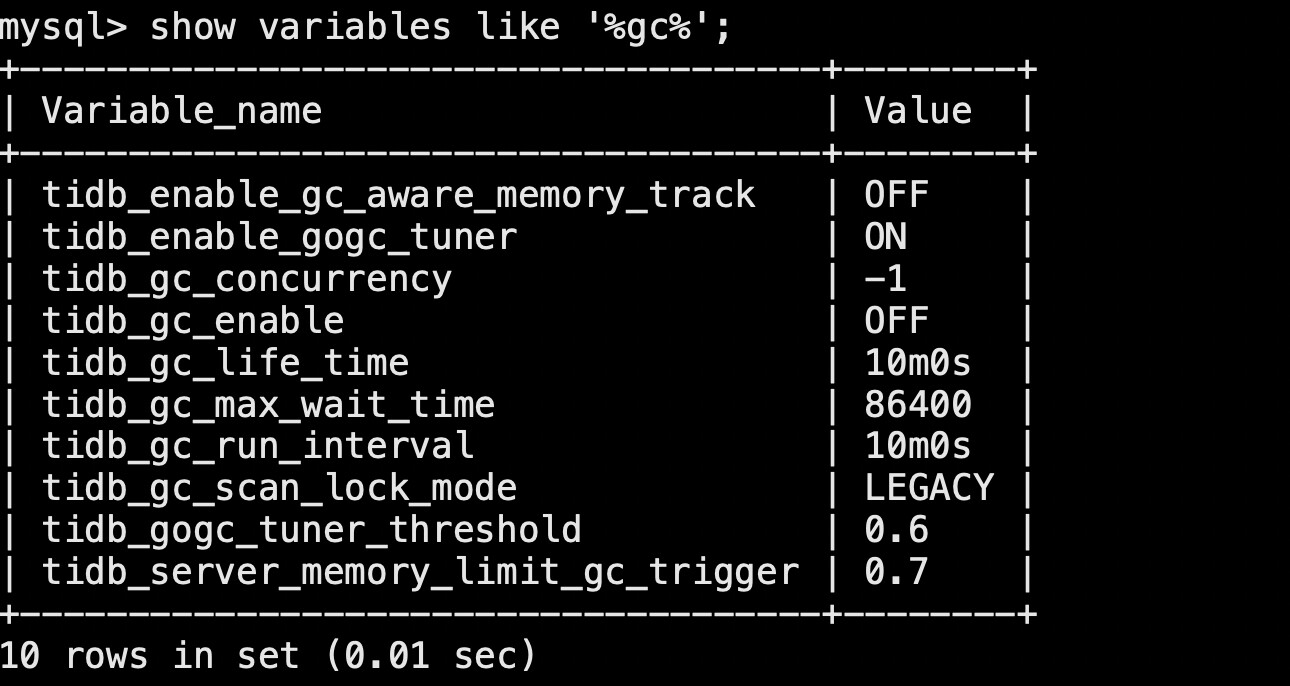
show variables like '%gc%';
vcdog
(Vcdog)
8
我们最开始做主从集群同步时,也是全部放到一个任务里,同步延迟或卡住时,出现的现象和你的很像。
后来,我们就把同步拆分成多个任务。
小龙虾爱大龙虾
(Minghao Ren)
9
开始起 TiCDC 的时候会有一个增量扫的过程,这个比较慢,你可以看下 TiCDC 的监控,观察下资源消耗,咔咔耗资源就没问题
1 个赞
vcdog
(Vcdog)
11
你这个10分钟的gc时间,肯定是不够用的。建议先修改gc时间长一些,然后,再使用br工具备份及恢复,再创建多个cdc任务进行同步。
vcdog
(Vcdog)
14
我之前做主从集群同步时,进行备份前后,都是一直开启Gc的。不建议关闭gc
这里介绍不了我
(持续学习)
15
建议你现在先看一下每个TiCDC节点上面的日志是个什么情况
vcdog
(Vcdog)
17
1.1T的数据,你备份和恢复,大概消耗时间是多少。要把这个时间预留出来,就是gc设置的时间大小。或者,最好稍大一些,比如设置24小时或48小时,全量恢复后,只追增量数据,应该很快。除非当时是遇到大事务或大批量的数据变更操作。
Denis
18
我们这边做主从也是开启的gc,调大GC,通过dumpling + lightning导入的方式做的
1 个赞
初来乍到
(Ti D Ber 4c Cgc Gp L)
19
后来扩容的cdc 到集群中,没有部署单独的cdc监控节点
监控看下这个位置 tikv-details > gc > tikv auto gc savepoint
1 个赞
初来乍到
(Ti D Ber 4c Cgc Gp L)
21
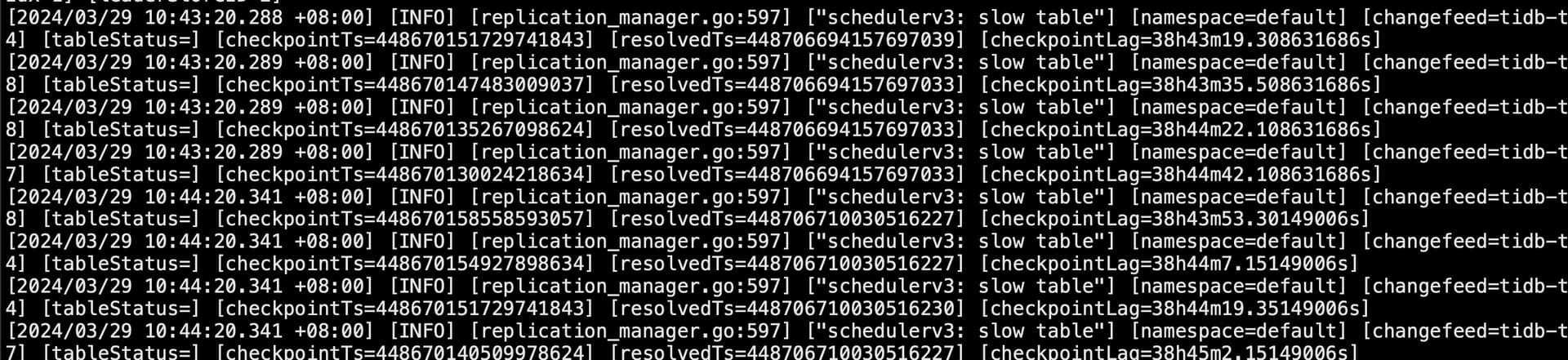
目前看 好像是这么回事查看日志,好像是一张表一张表的在追
然后按照对应的tableid查看,数据是有增长,同步进来的