【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.1.1
【复现路径】部署节点服务器重启,ticdc 服务正常重启
【遇到的问题:问题现象及影响】任务状态为normal,但是没有数据同步到下游,下游为 kafka,尝试 重建任务,重启 ticdc 节点,扩容 ticdc,均无效
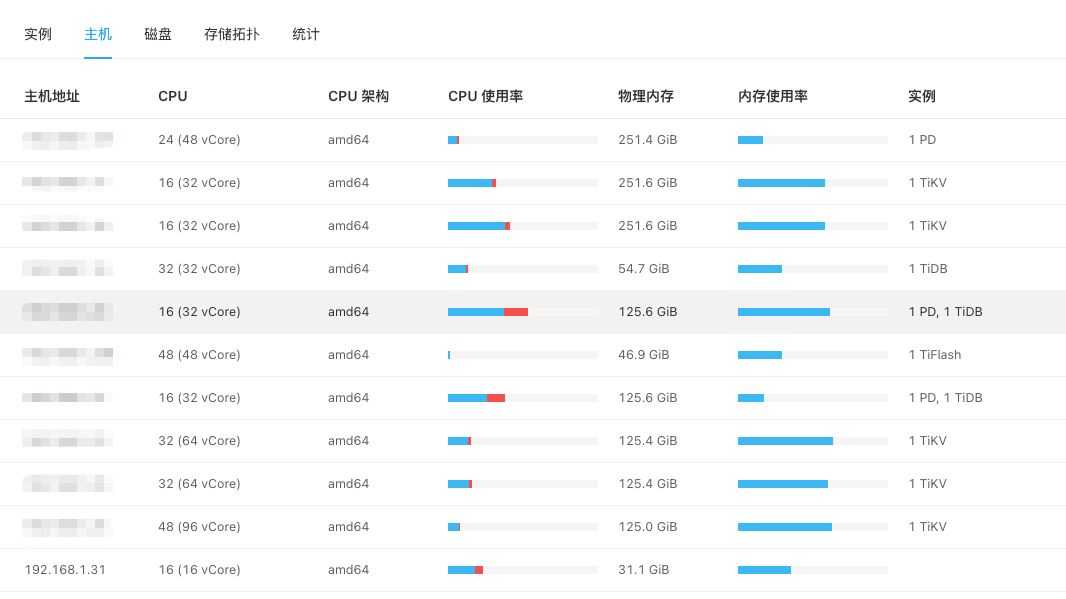
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
cdc 任务状态
cdc 日志
【 TiDB 使用环境】生产环境
【 TiDB 版本】v8.1.1
【复现路径】部署节点服务器重启,ticdc 服务正常重启
【遇到的问题:问题现象及影响】任务状态为normal,但是没有数据同步到下游,下游为 kafka,尝试 重建任务,重启 ticdc 节点,扩容 ticdc,均无效
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
cdc 任务状态
cdc 日志
现在这种状态,你要不要考虑直接安装 ticdc 新架构
请问新架构是什么
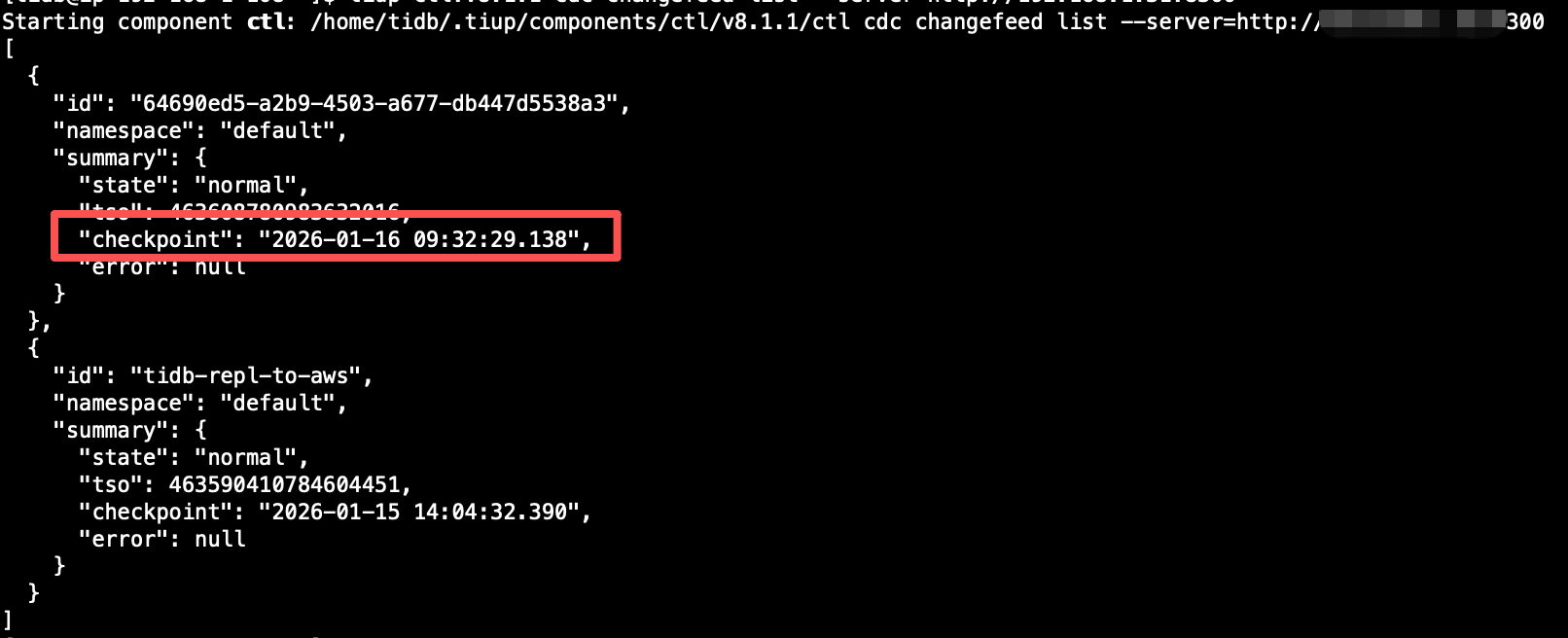
是 checkpoint 不推进了吗?一般你这种情况应该是哪里的配置搞错了
是的,请问有哪些配置会影响这个呢,因为一直也没改过参数配置
不推进的话看监控,看下 checkpointTs lag 和 resolvedTs lag,再看下 dataflow 面板 TiCDC 监控指标分析指南
我们也是遇到这种情况,ticdc 所在服务器自动重启后,checkpoint 一直没推进
无论怎么重启、重建,都不行,到底怎么排查呢
要确认同步的表是有 pk/uk 的,filter 是否设置正确?都没问题的话要查下上游了。
看下 cdc 监控的 tikv 面板和 DB 面板呢,磁盘是不是有问题呢
把日志也传下吧
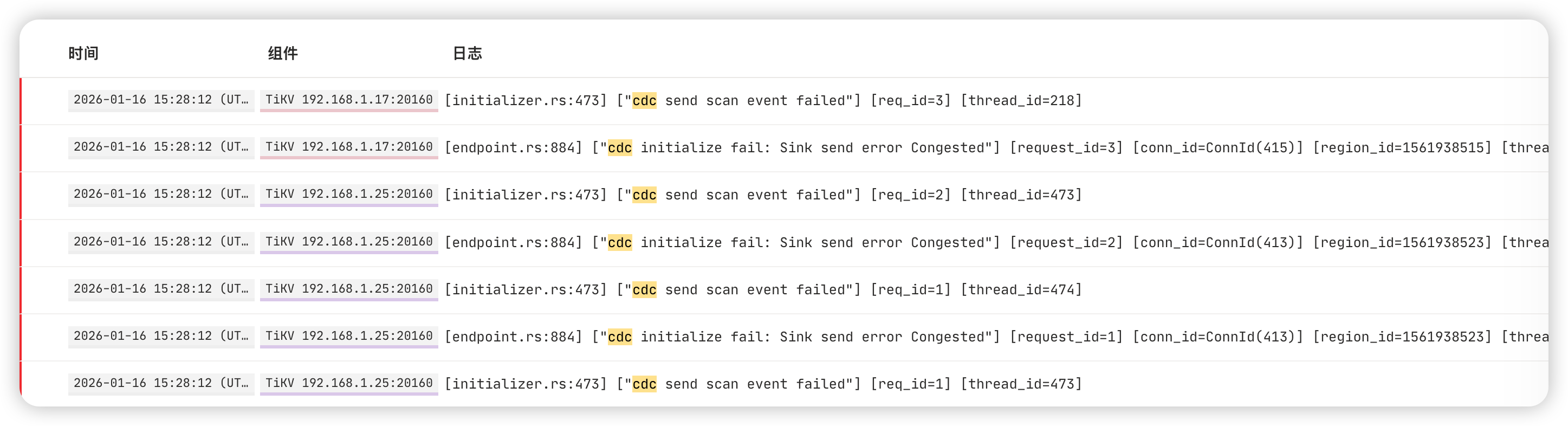
tikv 日志:
[2026/01/16 16:49:40.624 +08:00] [ERROR] [initializer.rs:473] ["cdc send scan event failed"] [req_id=39] [thread_id=345]
[2026/01/16 16:49:40.624 +08:00] [ERROR] [endpoint.rs:884] ["cdc initialize fail: Sink send error Congested"] [request_id=39] [conn_id=ConnId(89)] [region_id=1561938515] [thread_id=345]
[2026/01/16 16:49:40.624 +08:00] [ERROR] [initializer.rs:473] ["cdc send scan event failed"] [req_id=42] [thread_id=346]
[2026/01/16 16:49:40.624 +08:00] [ERROR] [endpoint.rs:884] ["cdc initialize fail: Sink send error Congested"] [request_id=42] [conn_id=ConnId(91)] [region_id=1561938515] [thread_id=346]
查到 1561938515 的 region_id 指向 mysql.tidb_ddl_job 表,但这张是空表
问题已经解决了,原因是 TiCDC 与 TiKV 之间的网络连接已满,导致变更数据无法从 TiKV 发送到 TiCDC TiKV 指向一个缩容的 TiCDC 节点,后面重启了所有 TiKV 节点,有个问题就是,TiCDC缩容之后,TiKV 为什么还会指向这个节点呢
| Kafka 连接异常 | TiCDC 日志中出现 dial tcp i/o timeout | 检查网络 ACL、防火墙规则,确保 TiCDC 节点可访问 Kafka 9092 端口 |
|---|---|---|
| 数据过滤规则错误 | 任务配置中 filter 包含了错误的库表排除规则 | 重新调整 filter 配置,确保需要同步的库表未被排除 |
| TiCDC 捕获节点异常 | 监控中 Capture Count 异常或节点状态为 down | 重启 TiCDC 捕获进程,或扩容新的 TiCDC 节点 |
| 上游 TiDB 日志 GC 过快 | checkpoint-ts 小于 tikv_gc_safe_point | 调整 TiDB tikv_gc_life_time 参数,或使用 --start-ts 指定晚于 GC 时间点重新创建任务 |
请问一下:
正常情况下,scale-in 一个节点,应该是会断开到这个节点的 grpc 链接的。
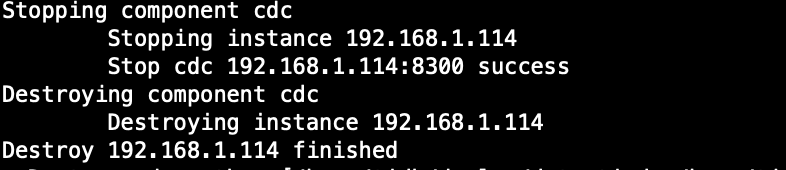
1、通过 tiup scale-in 114 这个节点 操作的
(tiup cluster scale-in test-cluster --node 192.168.1.114:8300)
2、当前 114 机器已经没有42309,42285 端口存在
3、通过逐个重启 TiKV 节点 的方式解决
不过之前重启 141 cdc 服务的时候有一个现象,blackbox_exporter-9115.service 会报重启失败,但是在机器上检查状态,这个服务也是起来的
我怀疑是 tiup sclae-in 这个节点的时候,可能部分失败了,即没有成功下线,具体原因未知。按道理来说,cdc 节点下线的时候,会断开 grpc 链接,然后 tikv-cdc 尝试发送数据失败,就会释放这个 grpc stream,从而回收 memory quota。
请你分享一下上面截图中的 tiup log 呢,如果还有的话,也可以给一下如下信息:
没有看明白具体问题啊