【 TiDB 使用环境】测试
【 TiDB 版本】v8.5.4
【遇到的问题:问题现象及影响】
创建 columns类型 partition 分发器 投递数据到 kafka,测试发现 partition 分发器并未按照预期结果投递, changefeeds 配置如下:
{
"sink_uri": "kafka://xxx/tidb_binlog_topic?protocol=canal-json&kafka-version=2.8.2&max-message-bytes=67108864&replication-factor=3",
"replica_config": {
"filter": {
"rules": [
"*.*"
]
},
"ignore_ineligible_table": true,
"sink": {
"dispatchers": [
{
"matcher": [
"*.*",
"!*.global_sequence"
],
"partition": "columns",
"columns":["global_seq"]
}
]
}
}
}
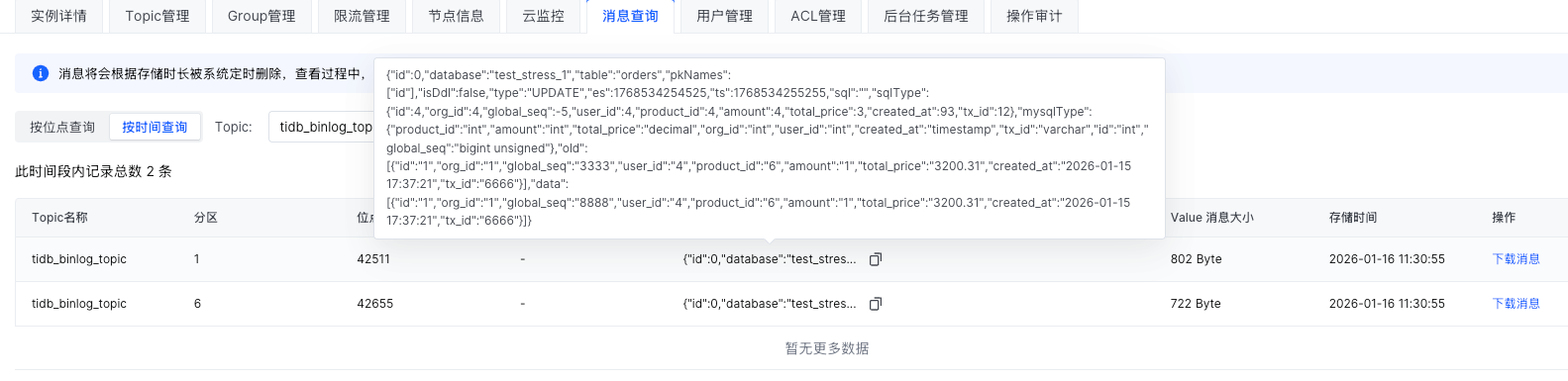
对应的kafka topic tidb_binlog_topic 有 12个分区 ,TiDB 测试脚本如下:
begin;
update orders set global_seq =8888 where id < 2;
update products set global_seq=8888 where id < 2;
commit ;
上述 操作 将 不同表的 两行数据的 global_seq 修改为相同值 8888,理论上 按照 global_seq 分发后应该被发送到同一个分区,但查看 kafka 消息发现 两行数据变更被分发到两个分区!