因为下游需要监听数据变更的需求,之前用的binlog,实时解析监听。
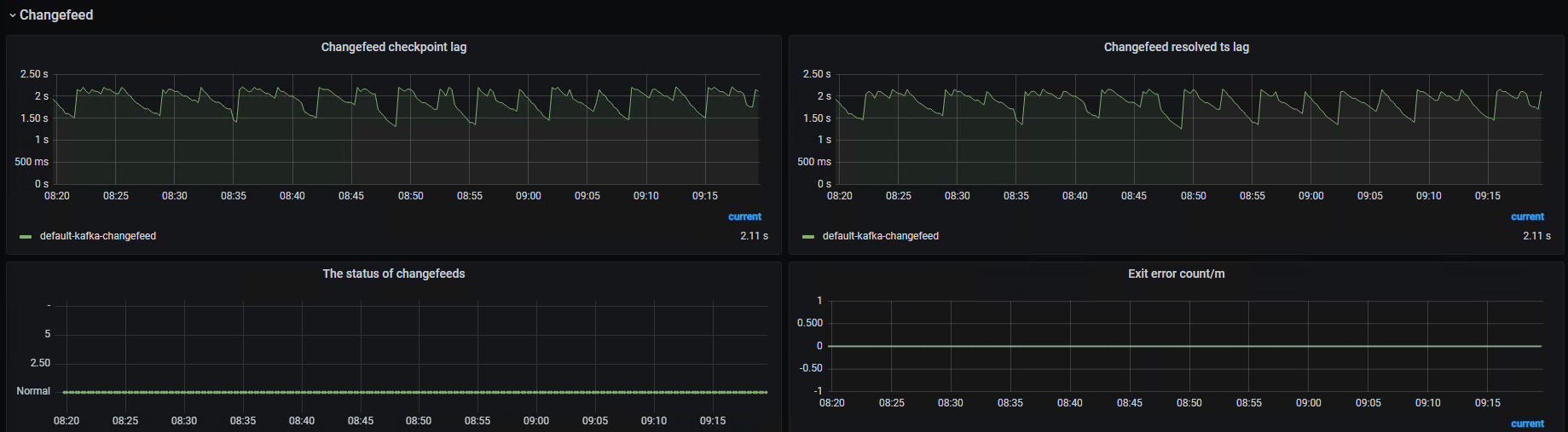
切换到tidb后只能用ticdc推送到kafka来实现监听,但是changefeed的推送延迟比较高,维持在2s上下,而且似乎和集群压力情况没多大关系。请问有办法降低延迟吗?
环境:tidb和kafka都在阿里云的同一个可用区和VPC下,网络应该是没有啥延迟的
因为下游需要监听数据变更的需求,之前用的binlog,实时解析监听。
切换到tidb后只能用ticdc推送到kafka来实现监听,但是changefeed的推送延迟比较高,维持在2s上下,而且似乎和集群压力情况没多大关系。请问有办法降低延迟吗?
环境:tidb和kafka都在阿里云的同一个可用区和VPC下,网络应该是没有啥延迟的
2S的延迟说实话的确挺高了,云平台是不是有数据限流的配置。
2s 如果不升高,不一定有问题的,可能是数据的版本太多了,需要获取到 特定 TSO 的数据,需要时间
多观察下
TiCDC 推送到 Kafka 延迟稳定在 2s 左右,且与集群压力无关,有可能是 TiCDC 自身的配置、调度策略或 Kafka 生产端的参数优化不足导致的。
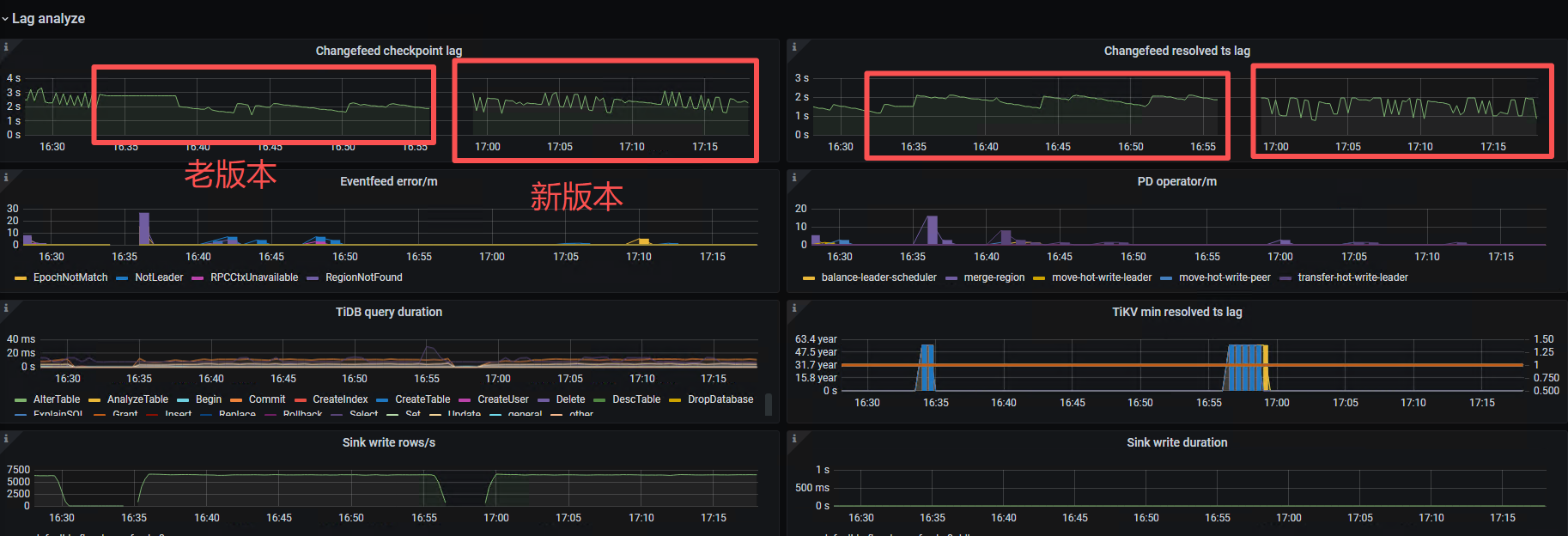
看你集群版本是 v8.5.5,不知道你用的 CDC 是老架构还是新架构,建议你用新架构
老架构本身设计上就会有 1S 延迟,调整 cdc.min-ts-interval 可以减少延迟,不过会增加流量,详细参考官方文档
如果用新架构,延迟应该是比老架构要好很多的,你可以测试一下,新架构参考:https://docs.pingcap.com/zh/tidb/stable/ticdc-architecture/
TiCDC 在 v8.5.5 之后的版本(如 v8.6.0+)对低延迟场景做了更多优化,若上述优化后仍不满足,可考虑升级到最新稳定版。
可以升级到新版本的架构试试
新架构基础消耗会高一些,数据量上来后会比老架构资源消耗少
新架构的延迟会好一点。监控上体现的值是因为心跳机制,上报会有一定的延迟。它实际写入下游会更实时一些。但是一定会存在抖动,不能保障的了非常的实时。
上游是否有长事务?
resolved-ts 推进机制(最常见)
sink(Kafka)flush/批量发送策略
TiCDC 默认参数偏保守
跨组件时钟/commit ts 推进节奏
![]() resolved-ts 推进间隔(核心瓶颈)
resolved-ts 推进间隔(核心瓶颈)
TiCDC不会立即发送数据,而是:
必须等 resolved-ts 推进,保证事务顺序正确
默认行为:
resolved-ts 推进大约 1s 级别
有 GC safepoint / tso / raft 等影响
![]() 这就已经吃掉 ~1s 延迟
这就已经吃掉 ~1s 延迟
![]() Kafka sink flush 间隔
Kafka sink flush 间隔
TiCDC Kafka sink 默认是批量发送:
关键参数:
[sink]
dispatchers = …
protocol = “open-protocol”
Kafka producer 内部:
linger.ms(批量等待)
batch.size
max.in.flight.requests
![]() 默认策略会再带来 ~1s 左右延迟
默认策略会再带来 ~1s 左右延迟
试试修改 Changefeed 的 sink-uri ,显式配置 Kafka Producer 的参数,强制其立即发送-
-sink-uri=“kafka://:/topic-name?kafka-version=2.4.0&partition-num=6&max-message-bytes=1048576&replication-factor=3&config=linger.ms=0&config=batch.size=16384”
如果改成立即发送是不是可以降低延迟,但是可能带来效率上的问题?