

随着医疗行业信创与智能化浪潮的推进,分布式数据库正成为医院数字化转型的核心选择。下面这篇深度分析文章,将为你解析这一趋势背后的原因与实践。
在数字化浪潮席卷全球的今天,医疗行业正经历一场深刻的变革。从电子病历的普及到智慧医院的建设,数据已成为驱动医疗服务质量与效率提升的核心引擎。然而,随着数据量的爆炸式增长和业务需求的日益复杂,传统的集中式数据库架构正面临前所未有的挑战。越来越多的医院开始将目光投向分布式数据库,这不仅是技术选型的变化,更是医疗行业迈向“数智化”时代的必然选择。
一、 现状之困:传统架构难以承载医疗数据的“新重量”
医院的信息化建设经历了从电子化、集成化到数据治理的演进。在早期阶段,以电子病历(EMR)和电子处方为核心,实现了手工业务的电子化,依赖于单机版数据库。随着HIS、LIS、PACS等系统的普及,进入了系统集成阶段,Windows与大型关系型数据库(如SQL Server)逐步替代了单机系统。而当前,医疗信息化正迈向数据治理与数智化的新阶段,如何让积累了二三十年的海量医疗数据发挥价值,成为新的课题 。
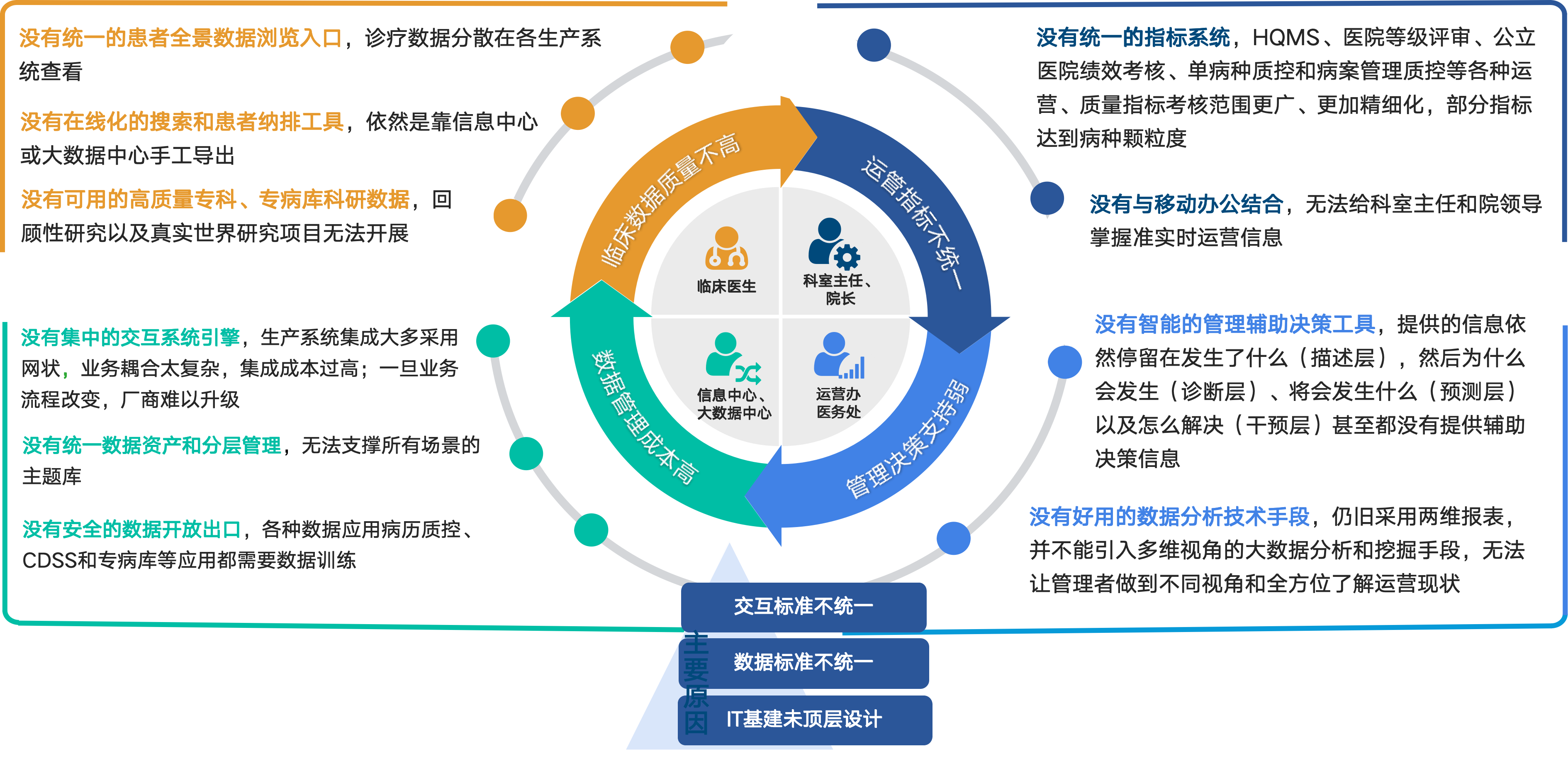
然而,在这一进程中,医院在数据处理和管理方面普遍面临四大困境:
- 临床数据质量不高 :医院积累了海量数据,但由于数据来源多样,涉及多个系统,且标准和数据指标不尽相同,大量数据处理工作依赖人工导出,真正能够投入使用的数据占比较少,数据质量亟待提高 。
- 运营指标不统一 :在运营管理过程中,缺少统一的指标系统,各类运营、质量指标考核难以细化;同时,数据分析和展现未能与移动办公结合,导致科室主任和院领导难以掌握实时运营信息 。
- 管理决策支持弱 :无论是临床决策还是管理决策,都高度依赖大量的数据支撑。然而,医院的信息化技术人员和信息科往往将主要精力集中在基础运维、网络维护以及系统日常维护等工作上,在数据本身的管理与挖掘方面投入的精力相对有限 。
- 数据管理成本高 :大部分医院没有集中的交互系统引擎,生产系统集成多为网状,业务耦合过于复杂,集成成本过高,一旦业务流程改变,厂商难以升级。同时,没有统一的数据资产和分层管理,无法支撑所有场景的主题库 。
医院数据处理和管理方面的困境如(图 1)所示 ,其核心是“数据管理应用不畅”,围绕这一核心,医院面临着数据质量不高、运营指标不统一、管理决策支持弱、数据管理成本高等多重挑战。
二、 分布式数据库的“对症良药”:五大核心优势
面对上述困境,分布式数据库凭借其独特的技术架构,为医院提供了一套“对症良药”。以平凯数据库(TiDB企业版)为代表的分布式数据库,其核心优势在于:
1. 原生分布式架构,从容应对海量数据与弹性扩展
传统的集中式数据库,如MySQL或SQL Server,在面对数据量持续增长时,会遇到扩展性瓶颈。它们采用垂直扩展的方式,即增加单机的CPU、内存和磁盘,但这种方式成本高昂,且存在物理上限。而分布式数据库采用“存算分离”的架构,数据被分割存储在多个节点上,计算能力也可以独立扩展。这意味着,当医院的数据量从TB级增长到PB级时,只需在线添加节点即可,无需停机重构,实现了像“搭积木”一样灵活生长。
例如,江苏省人民医院在建设全院ODS数据仓库时,需要承载来自HIS、LIS、病案、护理等18套生产系统的60TB业务数据。平凯数据库的原生分布式架构轻松应对了这一海量存储需求,并支持未来数据量的持续增长。
2. HTAP混合负载,一套系统兼顾交易与分析
医疗场景对数据库的需求是复合型的。一方面,需要支撑高并发的联机事务处理(OLTP),如门诊挂号、患者信息实时写入;另一方面,又需要进行复杂的联机分析处理(OLAP),如DRGs分组统计、单病种指标分析。传统方案往往需要构建“OLTP+OLAP”双栈,不仅架构复杂,还存在数据同步延迟的问题。
分布式数据库的HTAP(混合事务/分析处理)能力,通过一套架构同时满足这两类需求。它将行存(TiKV)用于事务处理,列存(TiFlash)用于分析查询,避免了数据在不同系统间的搬运,实现了数据的实时变现。在古珀科技服务的海南项目中,利用该特性将“全省异地就医动态分析”的查询响应时间提升了60%,10万级门诊数据的质控分析耗时缩短至30分钟内。
3. 金融级高可用与强一致性,保障医疗数据安全
医疗数据涉及患者隐私与诊疗决策,对数据一致性与可用性的要求极高。分布式数据库通过Raft协议实现多副本强一致性,确保单点故障时系统可自动恢复,实现业务的7×24小时连续运行。在北京市西城区卫生健康委的“区域云HIS”项目中,平凯数据库以1.45毫秒的极致响应速度和金融级高可用表现,在支撑超15000日均门诊量与7.2亿条数据的极限压力下,确保了核心业务的稳定运行。
4. 一体化数据平台,打破“数据孤岛”
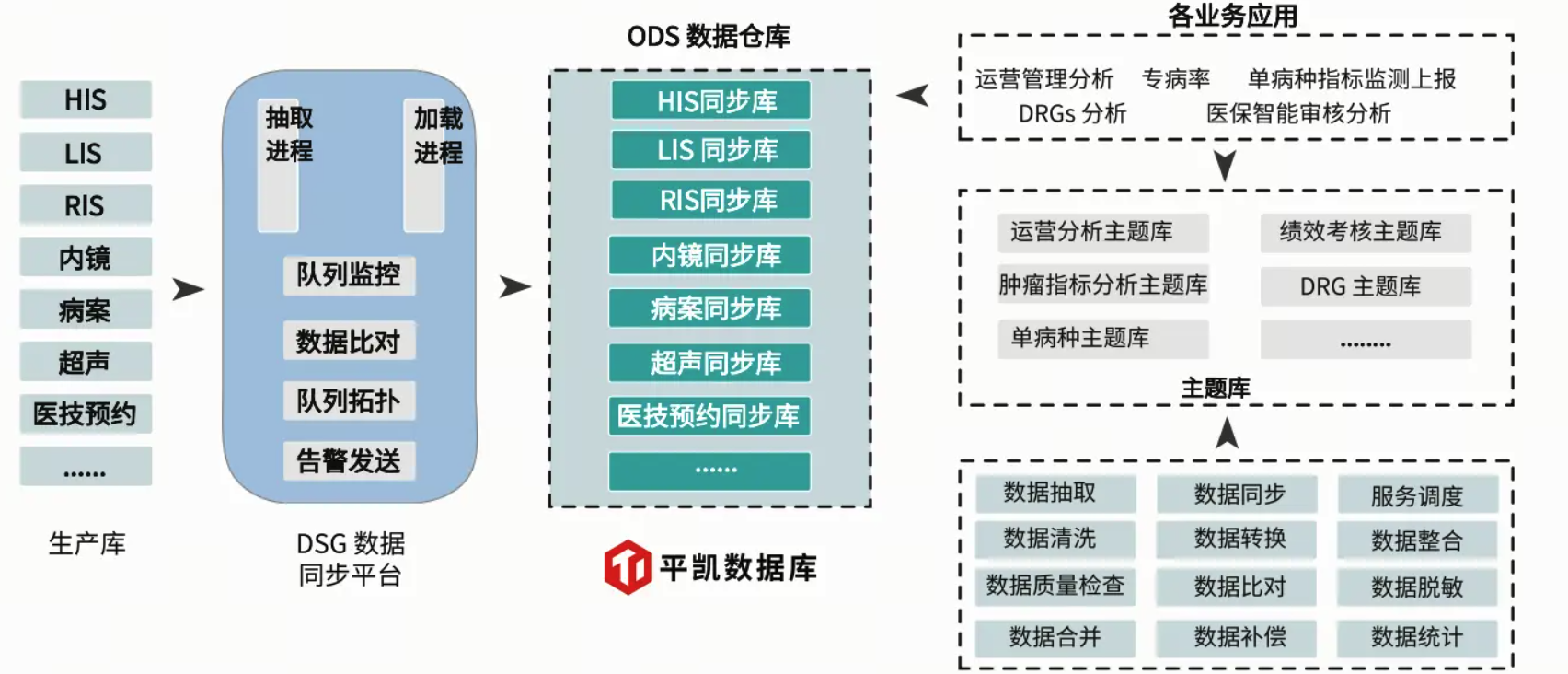
医院内部系统繁多,HIS、EMR、LIS、PACS等系统各自为政,形成了严重的“数据孤岛”,跨部门、跨机构的数据“互联互通”极其困难。分布式数据库通过构建统一的数据平台(如ODS数据仓库),可以将分散在多个生产系统的数据实时汇聚于一处,形成统一的数据视图,彻底打破“数据孤岛”。
例如,江苏省人民医院通过部署DSG数据同步平台,实现了18套生产库数据的抽取、清洗、转换与加载,最终汇聚成统一的ODS数据仓库。这使得科研平台可以直接调用多维度数据开展疾病研究,管理平台可以实时获取绩效数据,数据上报周期从“周级”缩短至“天级”。
5. 国产化适配,符合信创战略方向
在国家推动信息技术应用创新(信创)的大背景下,医院的核心信息系统面临国产化替代的要求。分布式数据库深度适配国内主流信创软硬件生态,支持通用处理器与操作系统,满足国家医疗行业自主可控的要求,为医院信息化建设提供长期技术保障。北京市西城区卫生健康委的“区域云HIS”项目不仅实现了数据库的国产化替换,更实现了从服务器、操作系统、网络设备的100%全栈国产化,筑牢了区域医疗数据的安全防线。
三、 实践出真知:标杆案例揭示转型价值
理论优势需要实践来验证。在医疗行业,一批领先的医疗机构已经率先采用分布式数据库,并取得了显著成效,为行业提供了可复制的转型模板。
案例一:江苏省人民医院——从“数据孤岛”到“实时数据平台”
江苏省人民医院作为江苏省综合实力领先的三甲医院,其业务系统已覆盖18套生产系统,日均产生海量医疗数据。为解决数据孤岛、实时性不足和扩展性压力三大挑战,医院选择平凯数据库建设全院ODS数据仓库。
该项目的核心成果包括:
- 数据效率显著提升 :复杂SQL查询性能大幅优化,月度数据质控等报表查询从分钟级到小时级缩短至快速响应;生产库压力有效降低,核心业务系统运行稳定性提升;数据供给时效从按周更新提升至按天更新。
- 赋能多场景应用 :60TB业务数据成为科研与管理的“金矿”,临床团队利用数据开展肿瘤用药规律研究,管理部门通过实时运营指标动态调整资源配置,公共卫生部门基于数据实现传染病快速追踪与预警。
- 树立国产化标杆 :该项目被评选为“2024信息技术应用创新优秀解决方案”,其“生产数据实时同步 + 分布式架构 + 主题库灵活扩展”的建设模式,为全国医疗机构提供了可复制的“数据中台”建设模板。
江苏省人民医院ODS数据仓库的架构如(图 2)所示,清晰地展示了从生产库到ODS数据仓库再到各业务应用的数据流转过程。
案例二:北京市西城区卫生健康委——“区域云HIS”打破物理边界
为实现区域医疗资源的集约化管理与高效协同,北京市西城区卫生健康委采用平凯数据库打造了“区域医共体云HIS”。该项目将辖区内11家医院(含6家三级医院)的核心业务重构为“云上联合体”,承载了超15000日均门诊量与7.2亿条数据的极限压力。
其硬核表现与价值跃迁体现在:
- 极致交易性能 :面对11家医院同时发起的高并发洪峰,系统对非加密数据的平均响应时间仅为1.45毫秒,在14,000+TPS的极限负载下,响应时间仍控制在5毫秒以内。
- 全栈国产化 :实现了从服务器、操作系统到网络设备的100%全栈国产化,标志着国产软硬件在医疗核心场景已具备完全替代国外产品的能力。
- 数智化红利 :分布式架构支持计算与存储资源的线性扩展,完美契合“医共体”不断生长的特性;HTAP能力打破了交易与分析的界限,实现了数据的实时变现,推动管理从“经验驱动”转向“科学决策”。
“区域云HIS”系统架构如(图 3)所示,核心为“双中台”数据+AI,为未来接入AI大模型辅助诊疗预留了充足的技术接口。

案例三:爱尔眼科——百倍性能提升,支撑全球最高门诊量
面对全球近千家医疗机构、日门诊量峰值超10万的巨大压力,爱尔眼科将核心业务从MySQL平滑迁移至平凯数据库,实现了业务“零中断”承接。
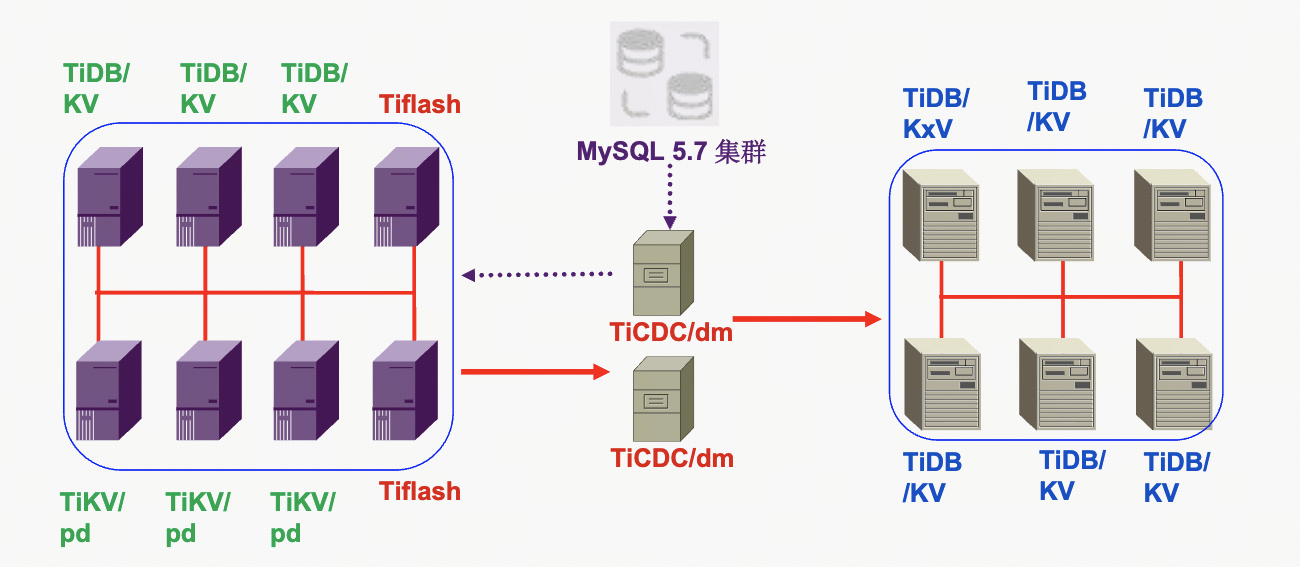
迁移后,查询性能实现了质的飞跃。以一个涉及多维度关联统计的复杂查询为例,在MySQL中耗时高达2分39秒,而在平凯数据库中仅需1.42秒,性能提升超百倍。此外,通过主备机房双集群部署,实现了机房级容灾,保障了极致的高可用。
爱尔眼科的“零中断”迁移方案如(图 4)所示,清晰地展示了主备机房的TiDB架构及数据同步流程。
四、 趋势展望:当信创遇上智能化,数据库成为价值上限
当前,医疗行业正站在一个关键节点。一方面是国产化带来的基础设施重构,另一方面是智能化带来的应用创新浪潮。在这两股力量交汇之处,数据库不再只是“支撑系统运行的组件”,而正在成为 决定数据价值上限的关键基础设施。
医院在推进国产化过程中,普遍遇到性能与扩展不足、架构单一、系统割裂等瓶颈。当AI应用逐步深入,这些问题会被进一步放大,因为AI不仅需要数据,更需要 高质量、实时、可统一调度的数据能力。因此,数据库选型不应只是“是否国产”,更应关注“是否面向未来”。面向未来的数据底座,需要具备统一能力(同时支撑TP、AP及AI负载)、弹性扩展、架构演进能力以及开放兼容等关键特征。
以平凯数据库为代表的新一代分布式数据库,正在提供一种新的可能:在满足国产化要求的同时,通过统一的TP+AP+AI能力,为未来智能应用预留空间。这一趋势在2026年第三十届中国医院信息网络大会(CHIMA)上得到了集中体现,“智能化”成为贯穿全场的关键词,大会明确指出医疗行业正在进入一个以数据与智能为核心驱动的新阶段。
江苏省人民医院信息处景慎旗主任在大会现场分享时强调:“高质量数据是人工智能的燃料。数据中心建设的核心,是为智能化提供持续支撑。”该医院早在2018年便引入平凯数据库,构建了“多模态、多中心、多场景”的数据体系,并在重症监护大模型、智能辅助诊断等场景加速AI应用落地。景慎旗主任在大会现场分享的场景如所示。
结语:数据敏捷,驱动医疗未来
越来越多的医院开始考虑分布式数据库,其背后的逻辑清晰而有力:传统架构已难以承载医疗数据的“新重量”,而分布式数据库凭借其原生分布式、HTAP混合负载、高可用、一体化平台和国产化适配等核心优势,为医院提供了从“信息化”迈向“数智化”的关键技术底座。
江苏省人民医院、北京市西城区卫生健康委、爱尔眼科等标杆案例的成功实践,不仅验证了分布式数据库在医疗核心场景的技术可行性,更揭示了其在提升运营效率、赋能临床科研、支撑区域协同以及保障数据安全等方面的巨大价值。
展望未来,随着医疗大数据应用的深化和AI技术的普及,分布式数据库将扮演更加核心的角色。它不仅是数据的“容器”,更是数据价值的“催化剂”,通过构建统一、实时、高效的数据平台,推动医院实现从“系统驱动”到“数据驱动”的跨越,最终为患者提供更优质、更高效的医疗服务。在这场医疗数字化转型的浪潮中,分布式数据库正成为连接业务与数据的关键纽带,助力医疗机构在“数据驱动的转型”中取得成功。