

这是2025年应该写完的内容,一直拖到了2026年才动笔,拖了很久了... 
话接上一回武汉专题的社区分享活动,我任主持,期间其实出现了颇多的挑战话题,大概的场景如下:
- 为什么 TiDB 会比 Oracle 慢?同样的数据规模,明明都是最优的SQL Query,查询要慢至少 3s
- 为什么 TiDB 对网络的要求会这么高?你们用的什么核心交换机,能够满足这么高要求的数据交换背宽
- TiDB 写入确实很快,但是针对数据规模较小的表,效率还不如 Mysql
- .....
试想在现场被一堆问题砸过来了,你会怎么反应呢?
很明显,对方是实干派,有诸多诉求,但是不得其门而入
为了缓和现场的气氛,我给出了答案:
- TiDB 的查询需要从不同的TiKV节点获取数据,而且不止一次,这样的场景对比 Oracle 直接走 I/O 通道,没任何优势
- TiDB 设定的场景,就是支持海量规模的扩缩容,大规模的数据调度就需要至少万兆交换机来支持,如果需要多网卡的场景,就至少是十万兆级别的交换机,同样网卡也需要支持才可以
- 参考 oracle 的回答,针对小表的处理性能上肯定不如 Mysql 的,但是新版的 TiDB 支持内存缓存,可以有效提速
回答是回答了,但是仍然不满意,不满意也正常,为什么 Oracle / Mysql 支持的场景, TiDB 就不支持呢?
因为 TiDB 默认就是 N 节点 N 实例的分布式模式,天然就需要大量的RPC实现数据交换。现场有些小尴尬,不过,我给出了另外一个答案,TiDB 还支持敏捷模式,不过还没发布,可以关注。
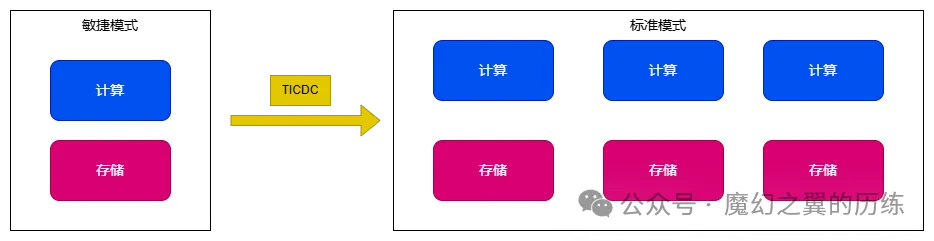
看到这儿,是不是发现痛点了,对,这就是 TiDB 以前最大的痛点,其实在社区的专项活动中,TiDB 的产品经理也分享过这个观点,如图:


敏捷模式,意味着TiDB 从原来未能支持的场景,打磨到可以支持,本身就是一种消除断层的跨越。
敏捷模式和标准模式最大的区别,就是 RPC 的数据交换替换成了 I/O,实现更小资源更快速的反馈,所以伸缩能力和规模会受到影响,但是仍然可以将数据快速的同步到 标准版,这样的模式能解决大部分的场景了。
再这个话题之后,接着平凯数据库(TiDB 商业版)就提出了下一个场景:聚能模式,如下图:


这三种模式到底有什么区别?通过图中,计算和存储所在资源的位置就可以判断出来,是针对要求更高场景的覆盖。
聚能模式是综合了敏捷和标准两种优势,极致的性能体验和可靠的扩缩容体验。
消除了IO问题带来的困扰,也能支持标准模式的自动扩缩容带来的弹性化体验,完全跨越了敏捷和标准两种模式带来的过渡问题,让应用的场景能够更加贴合实际的使用。


回到文中开头提到的问题,刚好印证这两种模式提出的背景,正面回应用户的需求就是最好的解决路径,没有之一。
从开源产品,跨越到商业产品,也是从痛点中寻找可能性和完善的方向,解决用户的问题来体现价值,这也体现了TiDB 成立之初的愿景:帮助客户实现价值和成就价值。
那除了这些痛点之外,还有其他的痛点么?有,还有很多很多....
在新品发布会上,仍然对产品和技术上有很多深入的思考,为什么需要做存算分离?为什么需要做解耦的处理?

只有解耦了,才能支持未来更多的场景和更多需求的迭代,不至于被绑住手脚,无法动弹,或者是瞻前顾后,无法会心一击。
存算分离在目前数据湖盛行的今天,不仅仅是时髦的代名词,确实能够帮助我们优化成本和减少一些非必要的管理和运维工作。
但是场景真的是太多了,但是需要寻找价值点和方向,能够适应市场的同时,还能兼容旧的体系,这件事情就很难。
结合产品发布会分享的内容,我预测可能会推进的点:
- 更加海量的场景突破
- 将冷数据存储迁移到S3,减少本地数据的副本和存储要求,节省资源
- TiFlash 和 TiKV 可以从同一份数据进行加载
- PD 核心服务剥离成 serverless ,减轻收集 Region 心跳带来的处理压力
- 更加极致的资源控制
- 组件会更小粒度,减少云上的管理和调度难度
- SQL资源单元模式
- 支持限定资源内,SQL 不被强制终止,一定能有运行结果
- 通用资源限定,针对租户或者用户能快速的抑制或者终止,保证集群的稳定

真的只有努力把事情做到极致,给用户带来更好更极致的体验,才会有获得认可的可能。
一棵树要长得更高,承受更多的光,它的根就必须深入更暗的土。
愿国产与开源数据库,在时代的光照下向下扎根、向上结果,让我们得以望见更广袤的发展天地。感谢这个时代,它把机遇和可能,悄悄放在了每一个奋斗者的掌心!
参考文章:
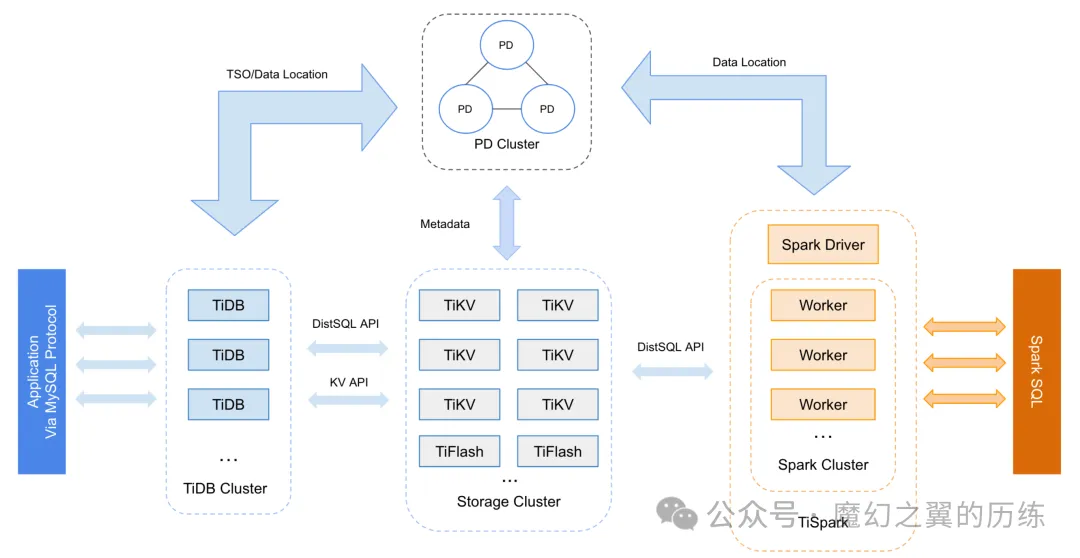
TiDB架构
https://pingkai.cn/docs/tidb/stable/tidb-architecture/
平凯数据库新产品解说
https://pingkai.cn/tidbcommunity/blog/66af6a2b
平凯数据库新产品发布
https://pingkai.cn/tidbcommunity/blog/4f4eea85